
AI is in overdrive. Models are scaling to absurd sizes, inference is getting laughably cheap, and nations are treating patents like Olympic medals. But beneath the surface, two key limitations are emerging: a looming shortage of high-quality training data and the growing environmental costs of scaling these systems.
This article breaks down the latest R&D trends, major players, and technical shifts shaping the frontier of AI, highlighting who's leading, who's catching up, and how the breakthroughs come with serious tradeoffs.
1. More Innovation in R&D: More Publications, More Patents
The past decade has seen AI evolve drastically. Between 2013 and 2023, AI publications exploded from roughly 102k to over 242k. AI now makes up 42% of all computer science research, and it's everywhere: in vision, language, robotics, theory, even human-computer interaction. If it runs on code, AI wants in.
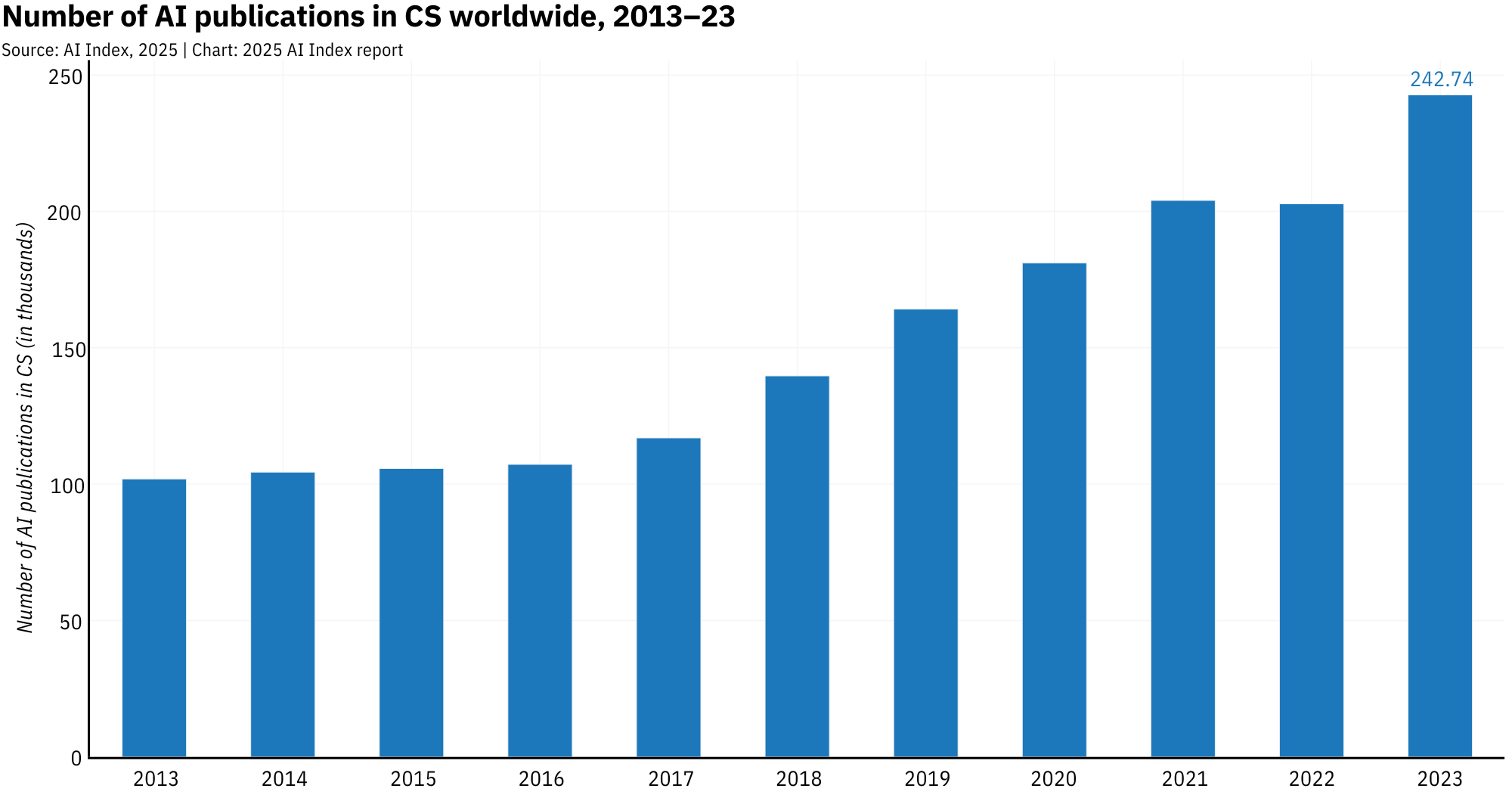
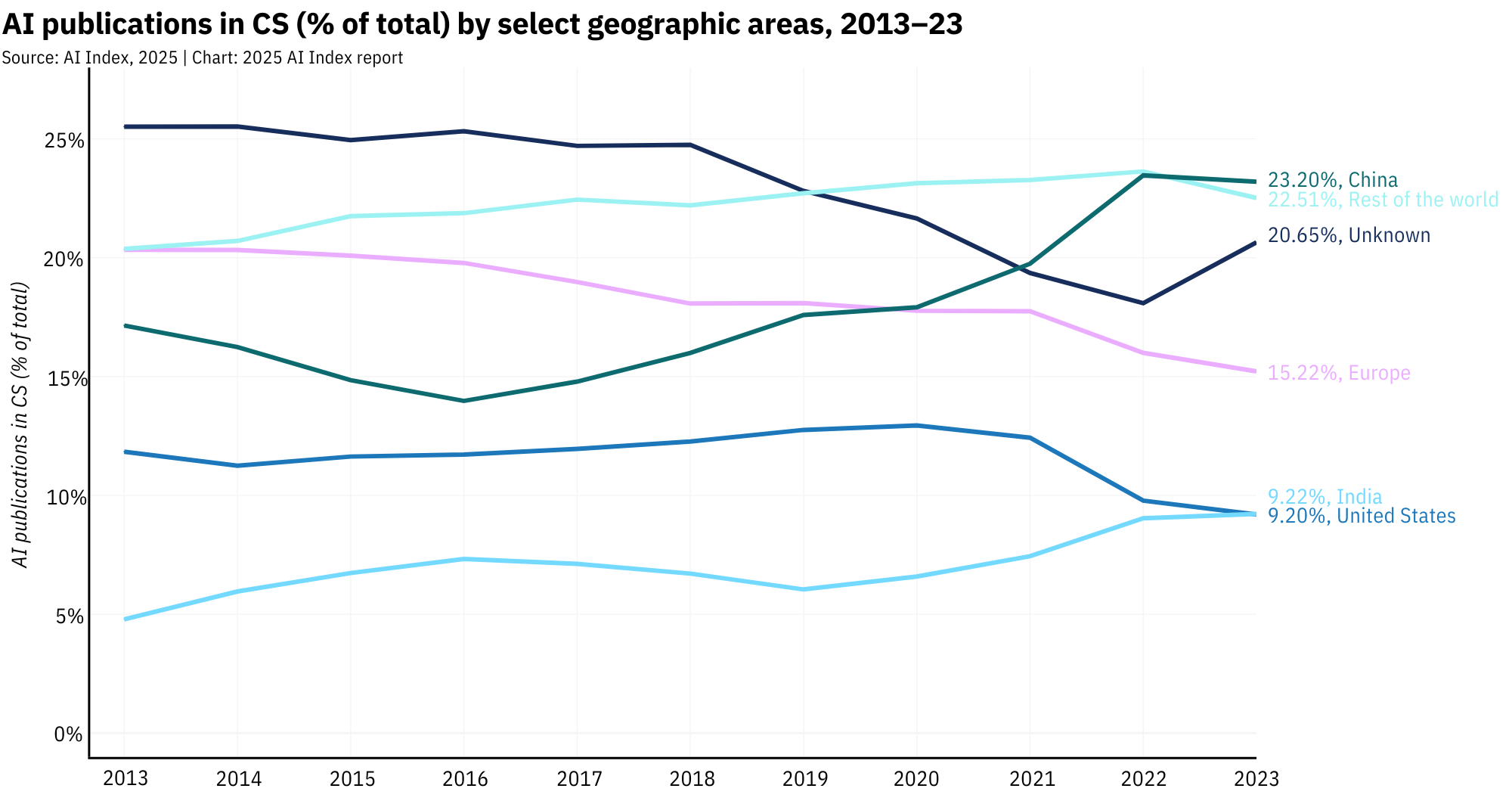
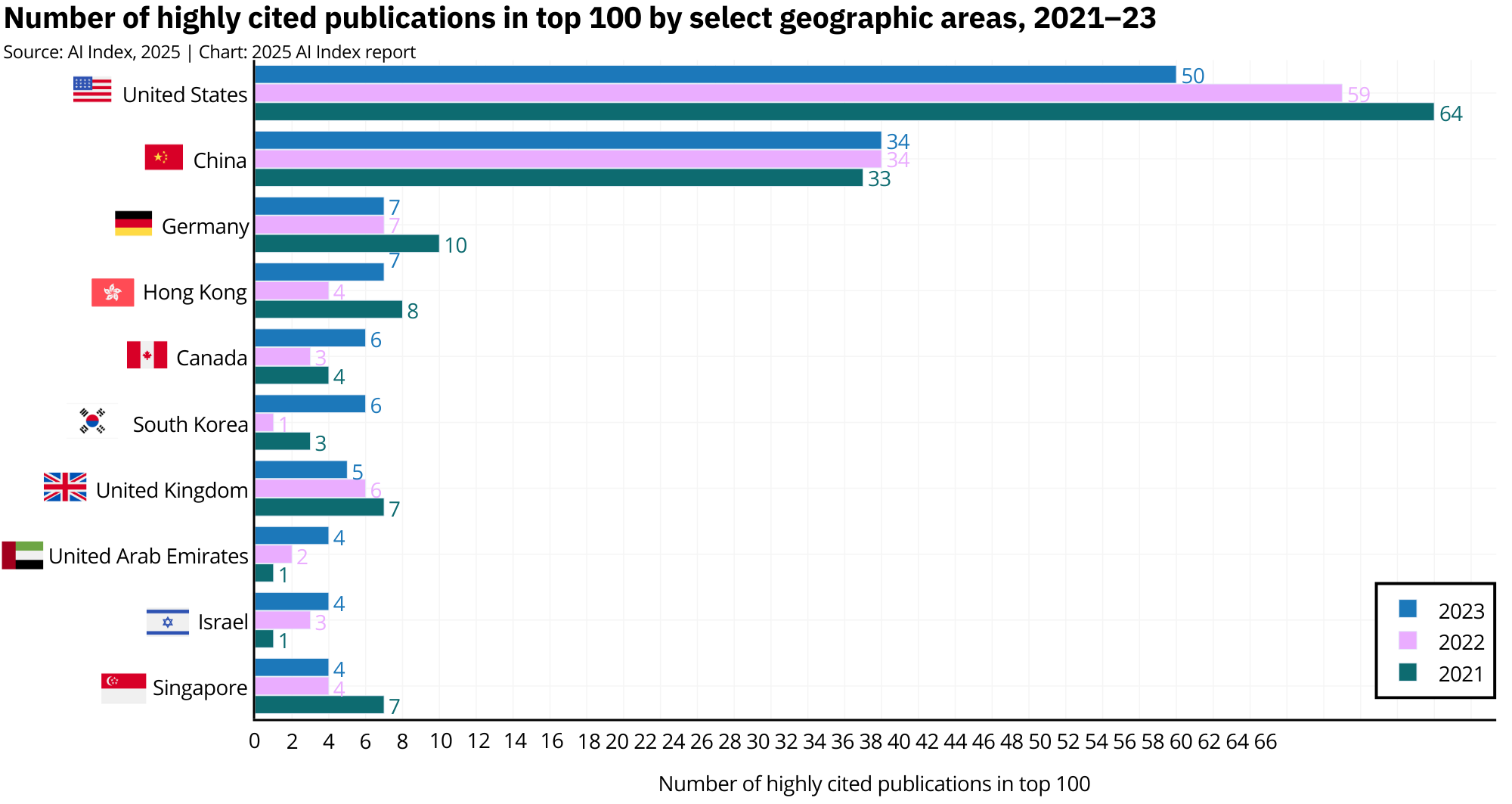
China now leads the charge on volume, churning out 23.2% of global AI papers and 22.6% of citations in 2023. But prestige still lives in the U.S., which produced more than half of the top 100 most-cited papers, mostly tied to the celebrity models of the moment like GPT-4 and Llama.
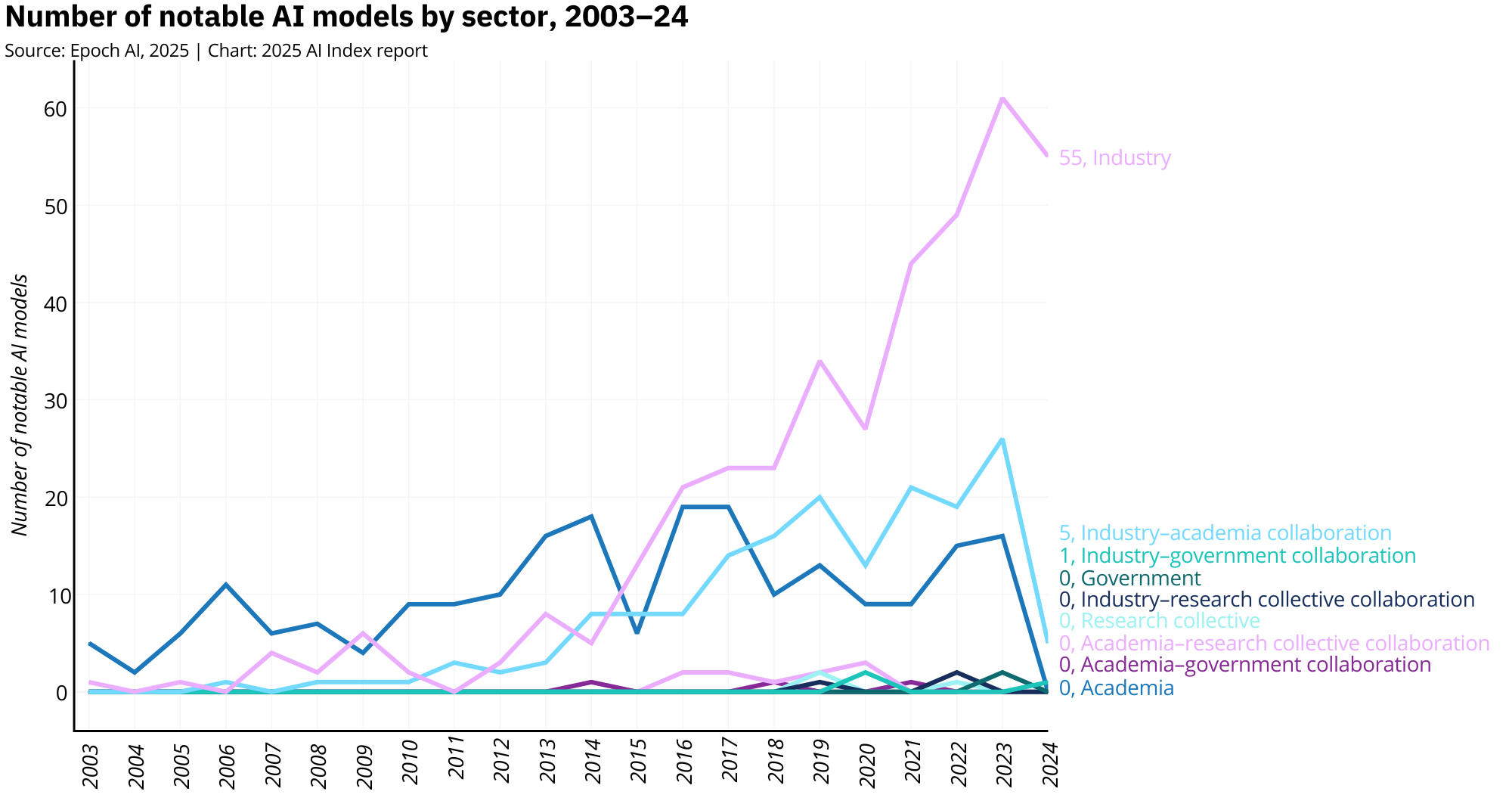
Then there's the shift from academia to industry. A decade ago, universities ran the AI show. Now? Not so much. In 2024, nearly 90% of notable AI models came out of corporate labs. The scale, the data, the compute, it's all in industry's hands.
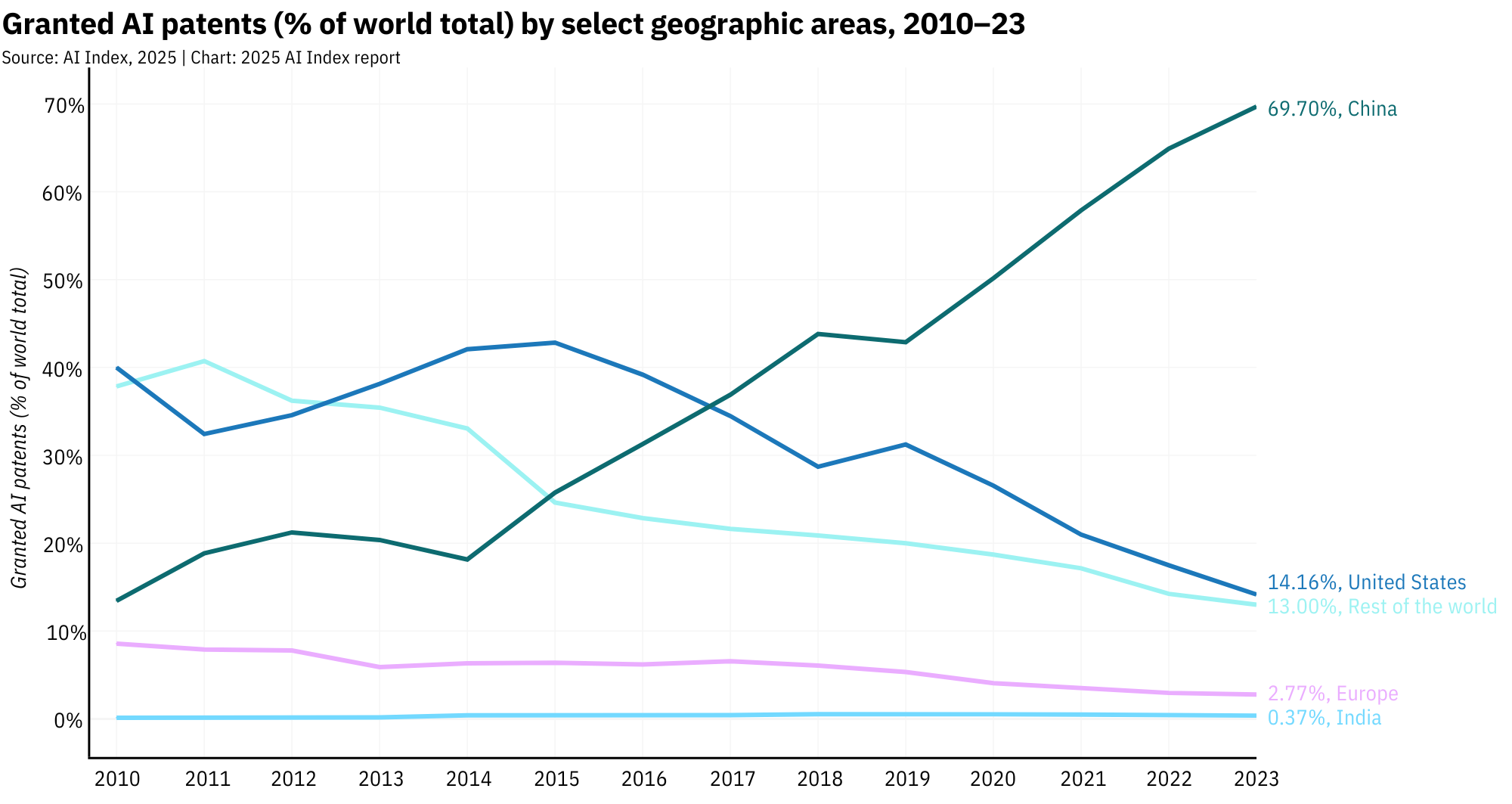
Patents tell a similar story. China granted nearly 70% of all AI patents in 2023, dwarfing the U.S.'s 14.2%. But this is driven by incentives. China rewards patent volume with subsidies, tax breaks, and bragging rights. The result? A mountain of paperwork and a very clear message: AI is national strategy now.
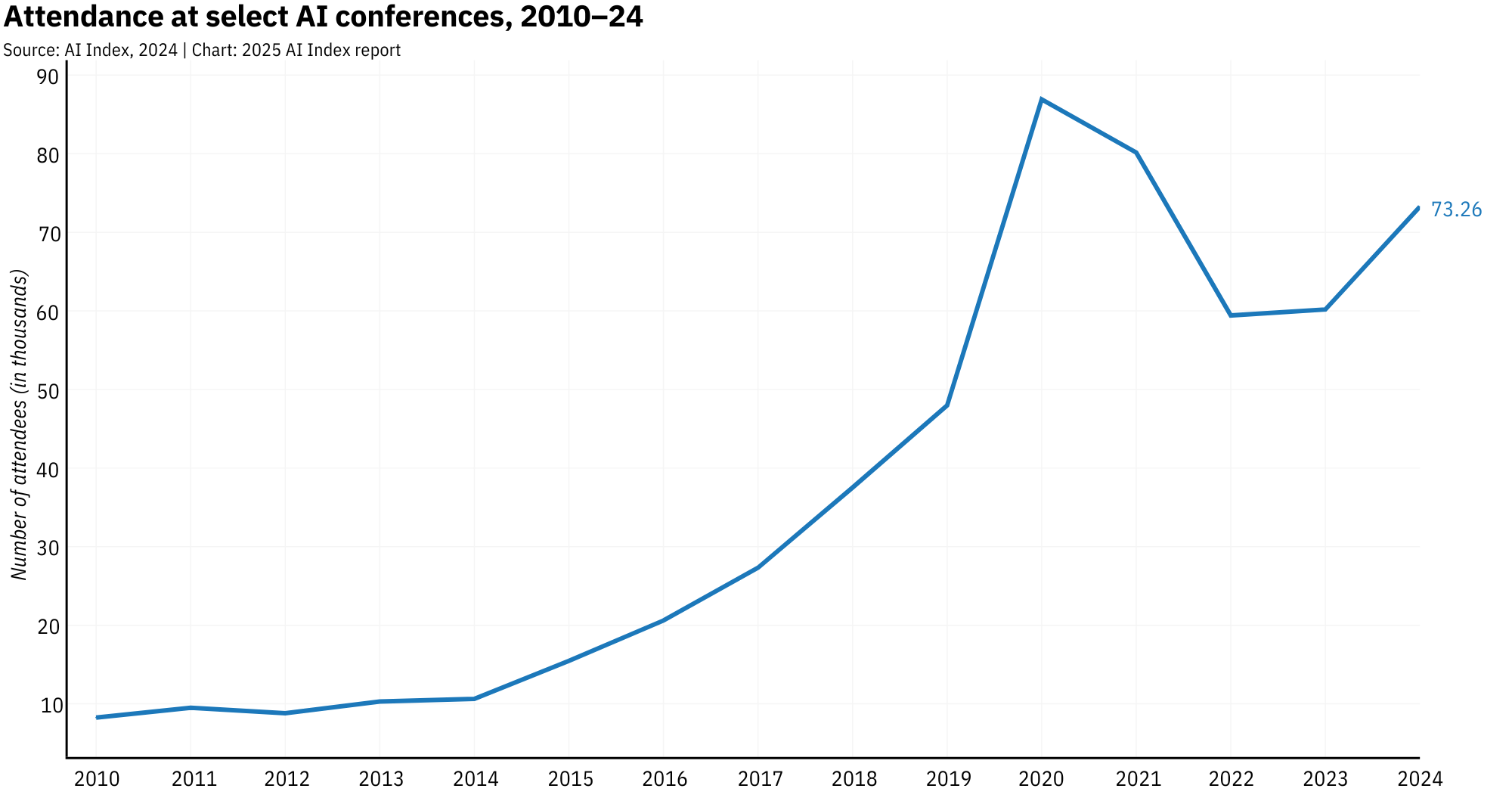
Meanwhile, AI conferences are swelling with fresh energy. Attendance at major conferences like NeurIPS and AAAI jumped 21.7% year-over-year in 2024, reflecting a field that's booming.
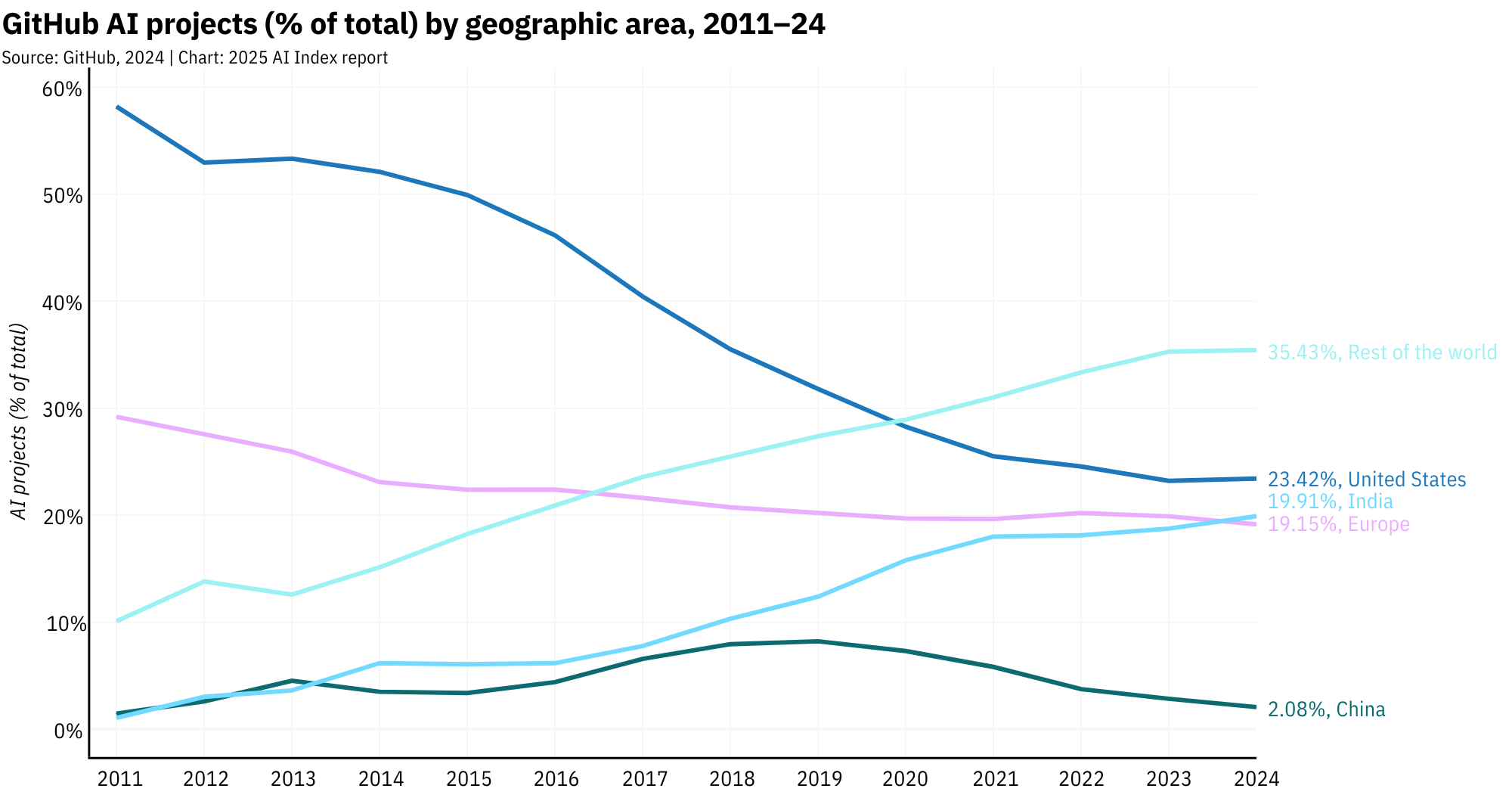
GitHub is also buzzing with AI activity, and the global open-source community is showing up. According to the AI Index 2025, contributions from the rest of the world (excluding the U.S., China, and Europe) now represent over half of all AI-related GitHub projects, a clear signal that the next wave of innovation may come from anywhere with a decent internet connection.
2. Always More: Bigger Models, More Compute, Better Hardware
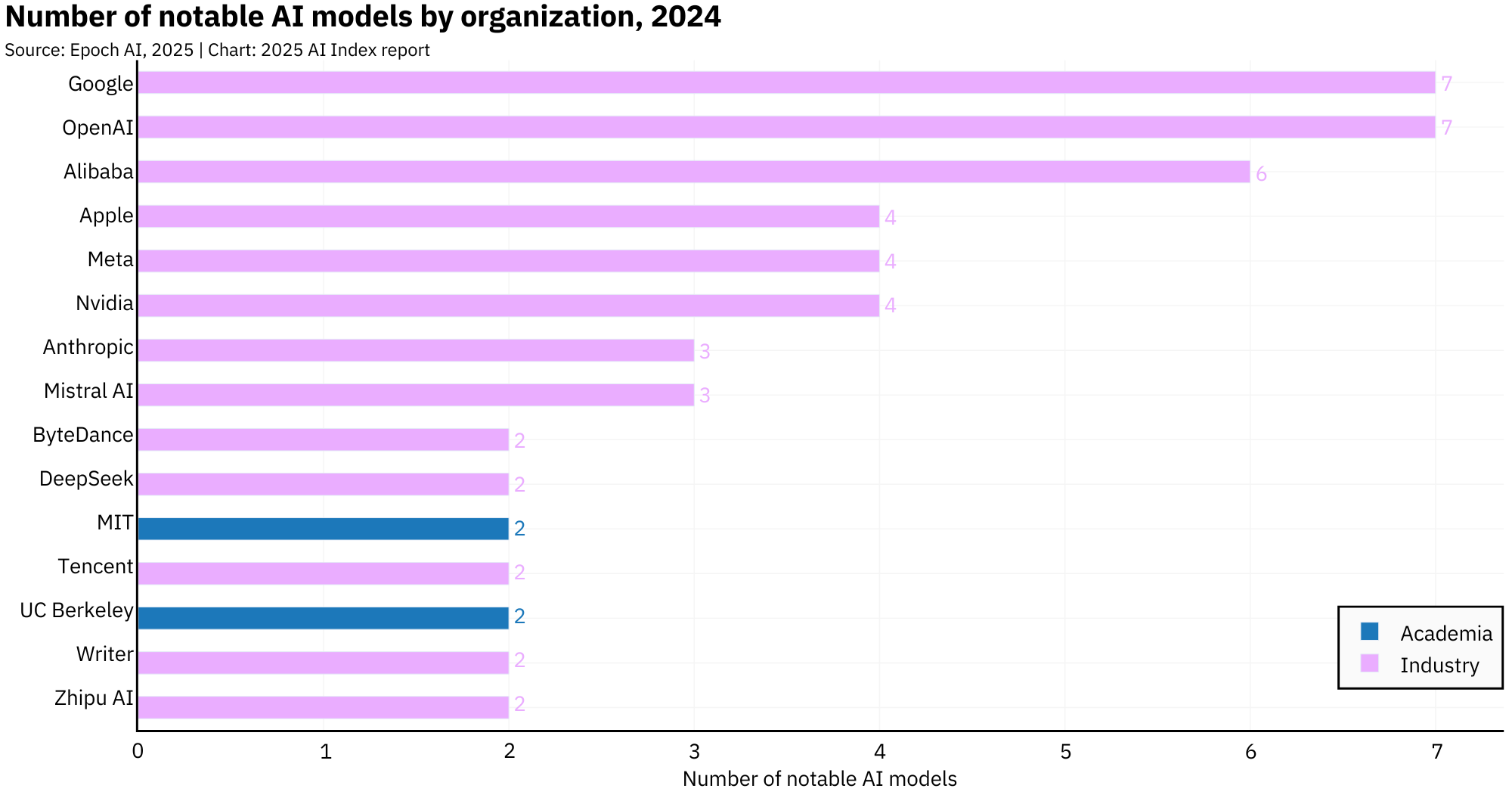
The field now runs on a single guiding principle: more. More parameters, more data, more GPUs, more power. In 2024 alone, 40 of the 61 notable AI models came out of the U.S., 15 from China. Academia? A total no-show. OpenAI, Google, and Alibaba led the parade. Mistral AI gave Europe a heartbeat. Thanks !
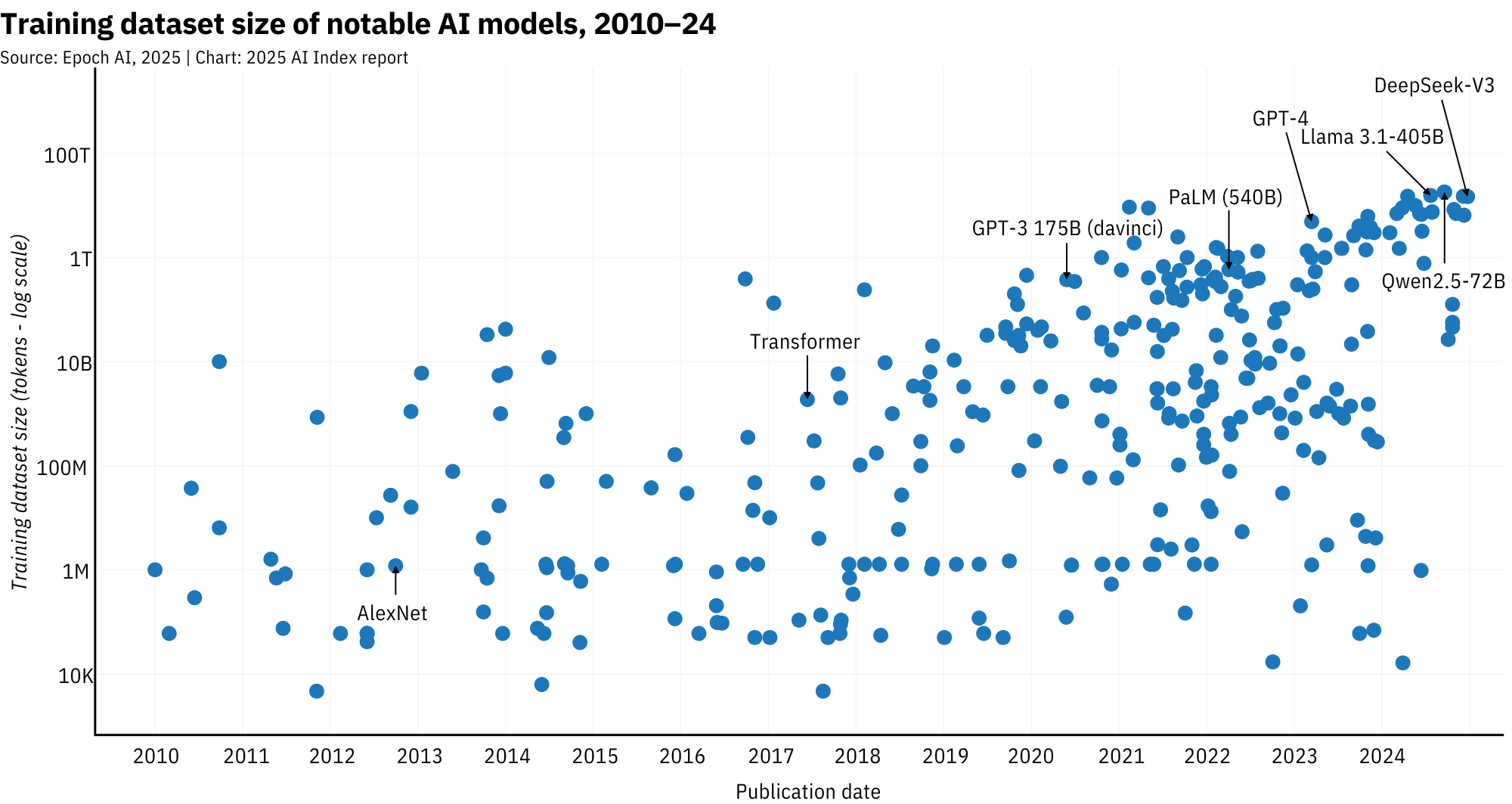
On the technical side, the scale-up is dizzying. The original Transformer (2017) was trained on ~2 billion tokens. Fast forward to 2024: Meta's Llama 3.1 is trained on 15 trillion. Llama 4 (2025) and Alibaba's latest? Bigger still. With Llama 4 Behemoth reaching a whopping 30 trillion tokens according to Epoch AI. That kind of scale means more compute and longer training: the original Transformer required ~1e20 FLOPs and was trained in about 3 days, while Llama 3.1 needed ~4.6e24 FLOPs and took roughly 21 days to complete.
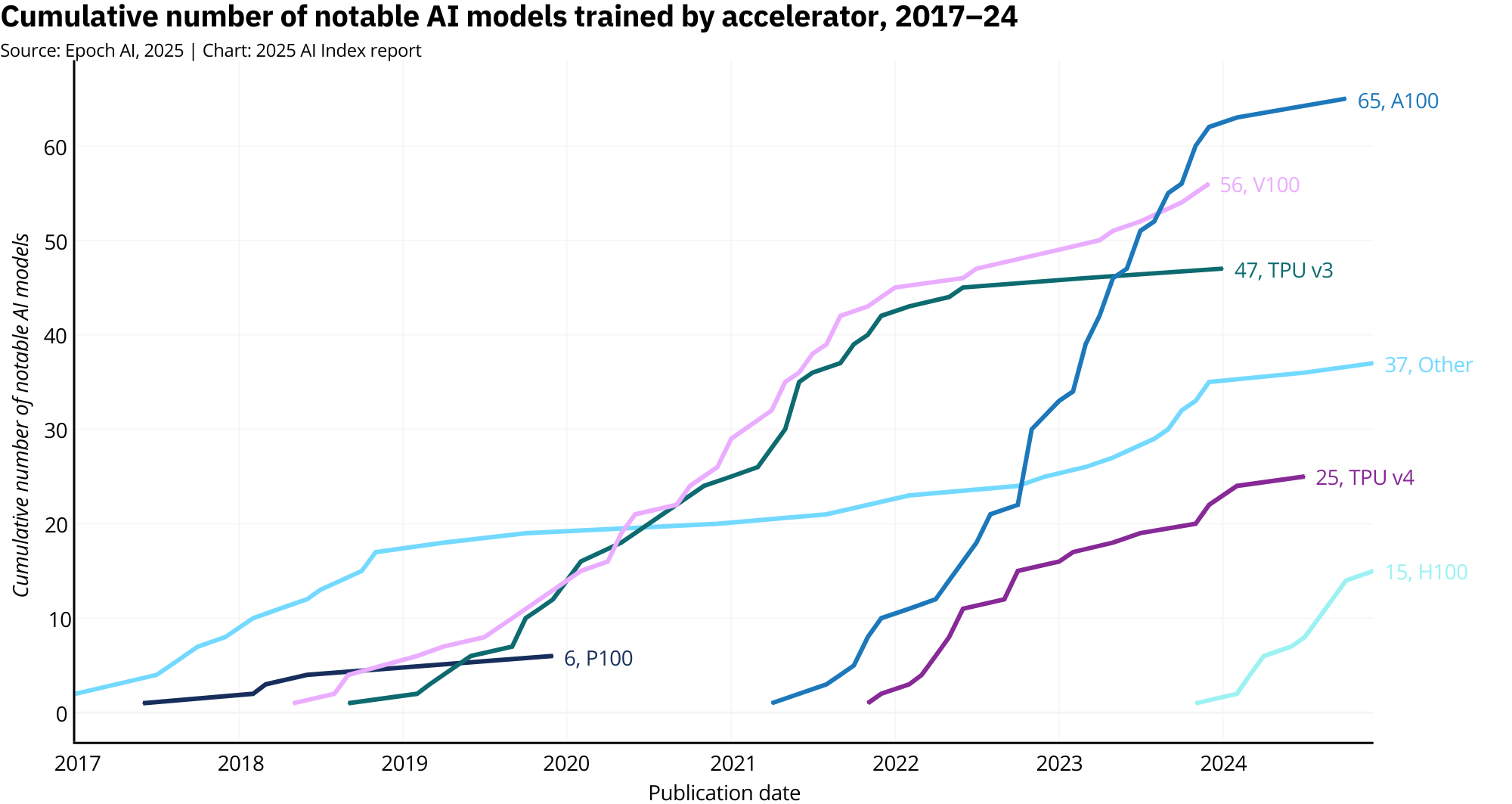
Of course, none of this happens without silicon. Nvidia's A100 chip (delivering around 312 teraFLOPs) was the default workhorse in 2024. But H-series GPUs like the H100 are setting the new standard with nearly 989 teraFLOPs, more than double the compute per chip, along with improved energy efficiency. Predictably, they also come with a much steeper price tag. Even consumer hardware like the new RTX 5090 is catching up in price-per-performance, though it still can't match the raw throughput or memory bandwidth needed for frontier-scale training.
3. The Great AI Cost Decline
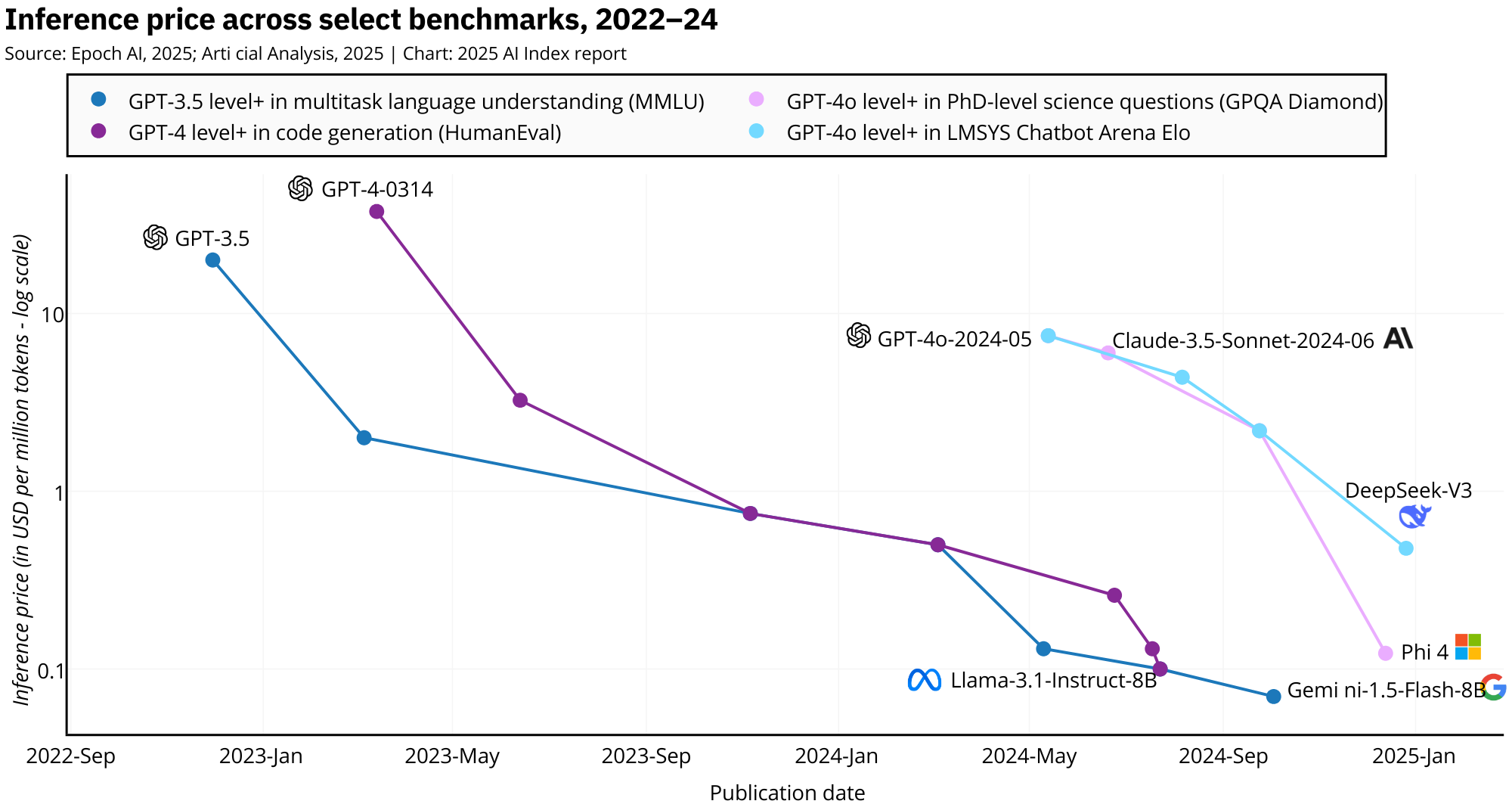
The cost of playing with AI is plummeting. Inference costs, which measure how much it costs to query a trained AI model, have taken a nosedive in recent years. For example, the cost to achieve performance equivalent to GPT-3.5 on the MMLU benchmark fell from a hefty $20.00 per million tokens in November 2022 to a mere $0.07 per million tokens by October 2024. That's right, a jaw-dropping 280-fold reduction in under two years. And this isn't a one-off; similar trends are popping up across different benchmarks, with costs falling by anywhere from 9 to 900 times annually, depending on the task.
What's driving this freefall in costs? For starters, hardware is getting seriously more efficient. On top of that, software optimizations and clever techniques like quantization, pruning, and knowledge distillation are squeezing every last drop of efficiency out of these models without sacrificing performance.
This cost plunge is shaking things up in the AI world. Suddenly, even smaller players and scrappy startups can afford to wield powerful AI models. It's democratizing AI, letting innovation bloom across all sorts of sectors. From personal assistants to enterprise solutions, AI is becoming less of a luxury and more of a standard feature.
So, if you're looking to jump into the AI game, there's never been a better time. Just make sure you've got a figure ready to show off just how steep this cost decline has been, something like "Inference price across select benchmarks, 2022-24" would do the trick.
With inference costs dropping like a rock, AI is no longer just the playground of the tech giants. It's open season, and everyone's invited to the party.
4. The AI Power Duo: China and the U.S. Take the Wheel
Despite the rhetoric of "global AI development," the actual scoreboard paints a different picture: AI in 2025 is still overwhelmingly a two-player game. China and the United States are dominating. Together, they drive the research agendas, build the models, file the patents, and pull the citations that shape the field. Everyone else is scrambling to keep pace.
Their dominance plays out differently. China has institutionalized scale: massive academic output, aggressive patenting strategies, and a government that treats AI like a national imperative. The U.S., meanwhile, blends elite academic research with a private sector that operates like a perpetual launchpad for the next headline model. If you're wondering who's steering the future of AI, it's these two, and they're not taking turns at the wheel.
The data makes it abundantly clear:
China produced 23.2% of all AI publications in 2023, the largest share globally.Chinese publications also accounted for 22.6% of AI citations, surpassing both Europe and the U.S.The U.S., while smaller in volume, dominated the prestige category: 50 of the top 100 most-cited AI papers in 2023 came from U.S. institutions.Over the past three years, the U.S. has led in top-cited AI papers every year, with China consistently in second place.In 2024, the U.S. released 40 notable AI models, according to Epoch AI, and China 15.Since 2003, the U.S. has produced more notable models than any other country, with industry giants like OpenAI, Google, and Meta at the center.China accounted for 69.7% of all AI patents granted worldwide in 2023, a patent tsunami powered by state incentives.The U.S., once a leader in AI patenting, has dropped to 14.2% of global AI patents, continuing a steady decline since 2015.China's patent growth is accelerating, with AI patent filings growing over 29% in just the last year alone.Tsinghua University and Google tied in 2023 for most top-cited papers from a single organization.U.S. industry produced 90% of notable models in 2024. Academia? A flat zero, according to Epoch AI's criteria.The U.S. also leads in compute-intensive models, with systems like GPT-4 requiring exponentially more FLOPs than Chinese counterparts.
This is about infrastructure. The U.S. and China have consolidated the resources that matter most: funding, compute, datasets, and talent. The result is a feedback loop where dominance begets more dominance.
But the rest of the world isn't staying quiet. Europe is stirring, with startups like Mistral AI and open-weight initiatives building momentum. South Korea and Luxembourg are outpacing many larger countries in patents per capita. The UAE and Singapore are carving out niche influence with strategic investments. India, meanwhile, is ramping up both research output and engineering contributions, with its AI publication volume now rivaling Europe's, and its GitHub activity reflects a growing base of open-source contributors that's hard to ignore.
It's still a U.S.-China show, but the stage is getting more crowded.
5. Scaling Has a Price: Data Limits and Dirty Training
AI's growth has been a rocket, fueled by more data, more compute, and more ambition. But like any rocket, the burn can't last forever. Two limits are now looming in the background: one technical, the other environmental. The first is the growing realization that we may simply run out of high-quality data. The second? All this progress is leaving behind a massive carbon footprint.
The Great Data Squeeze
For the past decade, the formula for progress in AI has been refreshingly simple: feed bigger models bigger datasets. And for a while, that worked. But as model sizes have exploded, the demand for training data has gone from large to absurd.
Back in 2017, the original Transformer was trained on around 2 billion tokens. Fast forward to 2024, and Meta's LLaMA 3.1, clocking in at 405 billion parameters, was trained on 15 trillion tokens. LLaMA 4 Behemoth, due in 2025, pushes that even further, reportedly topping 30 trillion tokens.
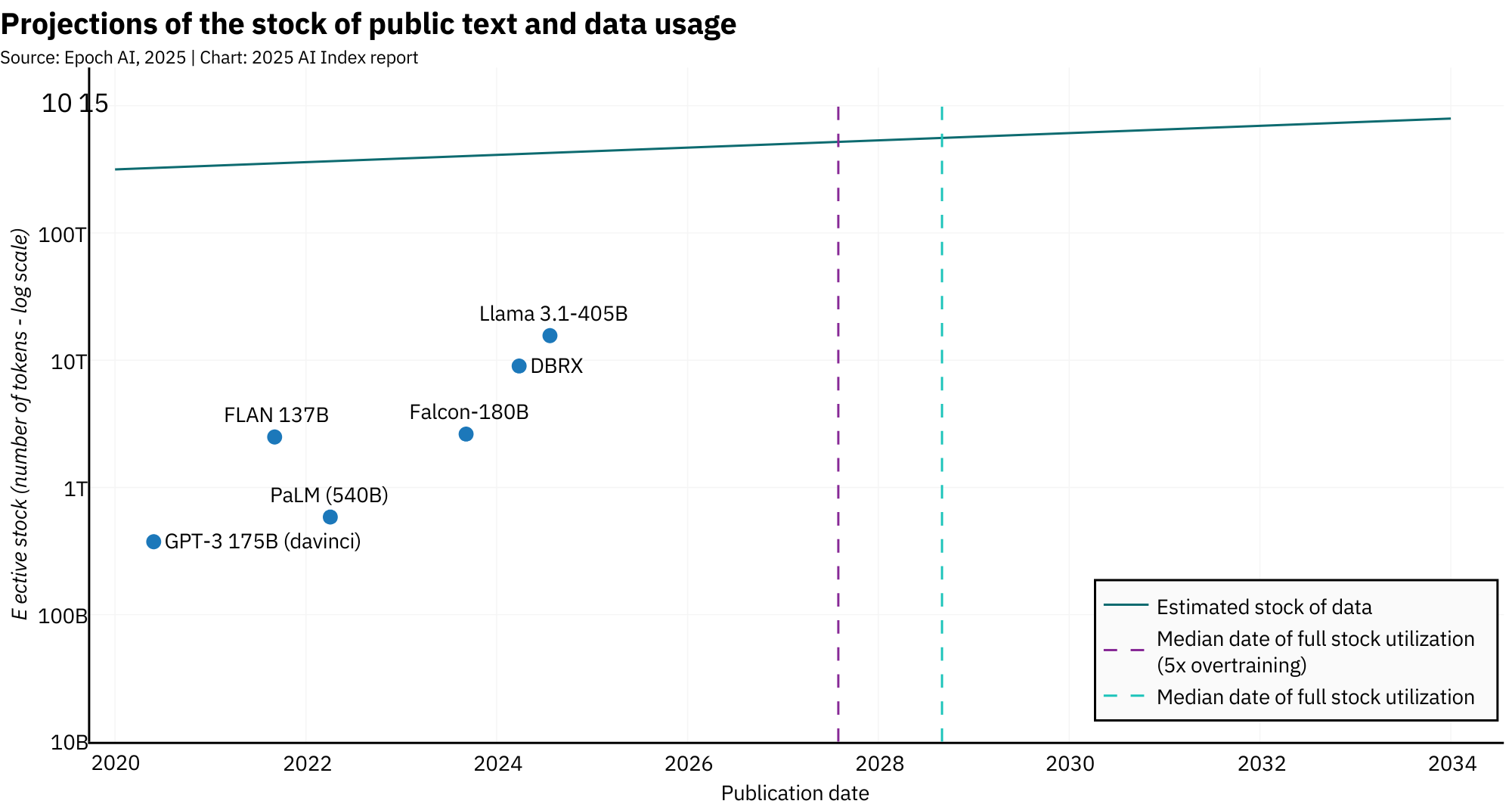
According to Epoch AI, LLM datasets are now doubling roughly every eight months. That trajectory runs headfirst into a hard limit: the actual amount of high-quality text available on the internet. At current rates of growth, the AI Index report projects that usable text data could be depleted between 2026 and 2032. And that's without factoring in the increasingly common practice of overtraining models, extending the training phase beyond typical convergence to improve inference efficiency. It's effective, but it burns through data faster than ever.
Some, like Mistral AI's CEO Arthur Mensch, argue that the panic over data scarcity is somewhat overstated. In a recent interview, he explained that while maximizing data made sense in the early days, because it was the most efficient way to boost model performance, it's no longer the only path forward. Improvements can now come from better model architecture, more efficient orchestration, and smarter sampling techniques. For French-speaking readers, the full interview is available here.
Still, even the more optimistic voices admit that most future data will be synthetic, i.e. generated by other AIs. And that introduces new problems. Models trained entirely on AI-generated content tend to reinforce mediocrity. They miss edge cases, flatten nuance, and often drift into a kind of statistical echo chamber. The AI Index notes that while synthetic data can help, especially when mixed with real-world text, it's no substitute for high-quality, human-authored material.
In the long term, this makes the future of AI less about training and more about implementation. With inference costs falling at breakneck speed, the smartest players aren't necessarily building new models. They're building on them.
Startups like Perplexity , Cursor , Gamma , and Lovable aren't investing in GPU clusters or trillion-token datasets. Instead, they're stitching together existing foundation models with interfaces, workflows, and user-centric tools. They're showing that value is in how models are used, who it's used by, and how fast it can be deployed.
In other words, the next wave of AI breakthroughs won't come from who can scrape the most data. It'll come from who can do the most with what's already out there.
The Carbon Cost of Scale
Maybe running out of training data won't be the worst thing, at least not for the planet. Because while the AI world is still busy chasing scale, there's another accelerating metric that doesn't get a flashy product launch: carbon emissions.
The AI Index 2025 makes this abundantly clear. In 2012, training AlexNet generated a negligible 0.01 tons of CO2. GPT-3 pushed that number up to 588 tons in 2020. By 2023, GPT-4 emitted an estimated 5,184 tons. And in 2024, Meta's LLaMA 3.1-405B produced an eye-watering 8,930 tons of CO2 during training, making it one of the most environmentally costly models on record.
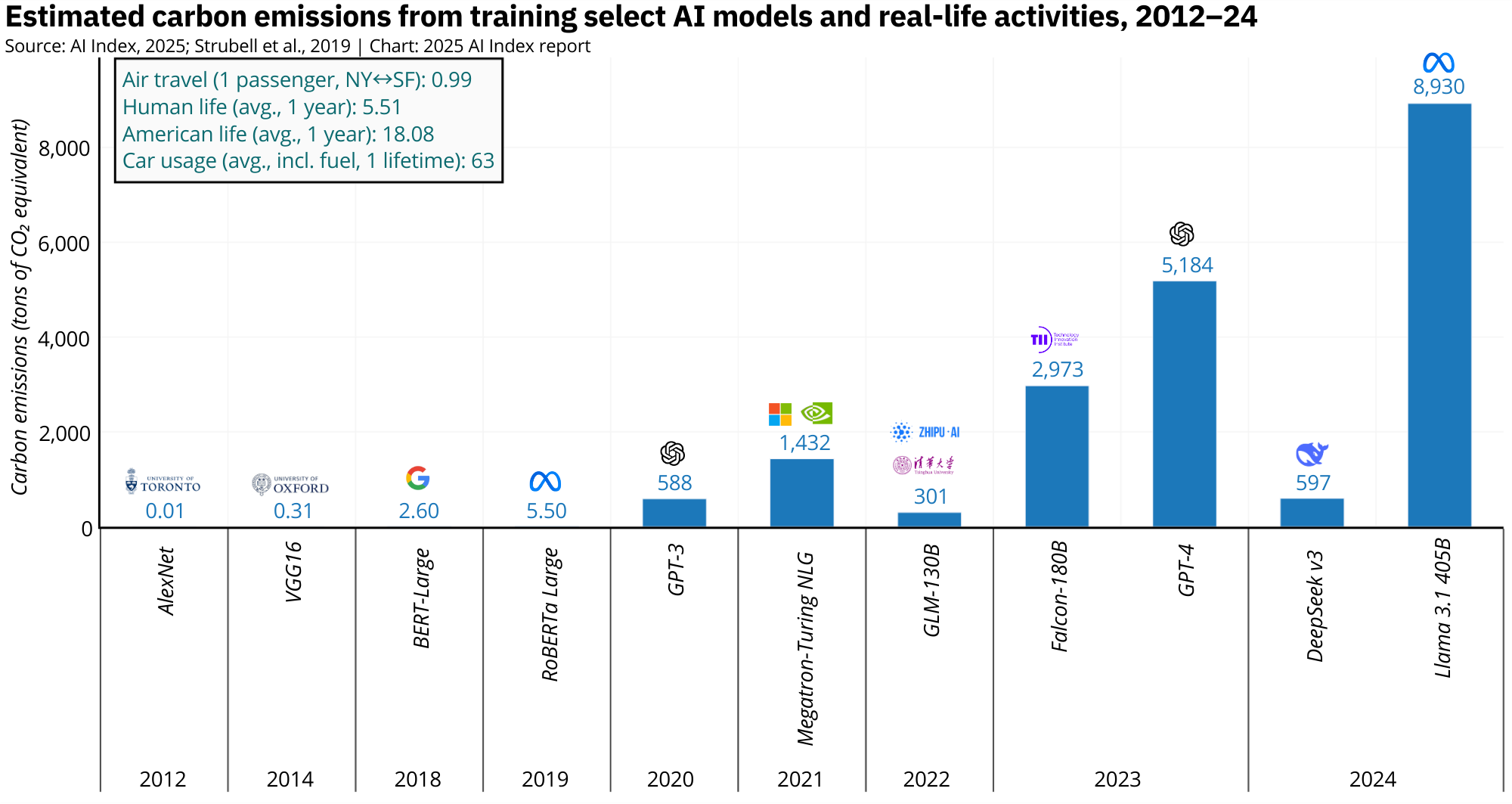
That's already substantial, but Grok 3 makes it look like a warm-up round. While there's no official emissions figure for Elon Musk's 2025-era Grok 3 model, we do know its estimated power draw during training: approximately 154 mega-watts. For comparison, LLaMA 3.1's training draw was around 25 mega-watts. That's more than a sixfold increase in instantaneous power usage, suggesting a training setup orders of magnitude larger in terms of compute and energy needs.
Even with modern chips like Nvidia's H100, which are significantly more efficient than the A100s that dominated in 2024, the sheer volume of hardware now deployed in model training is overwhelming any efficiency gains. The chips may be greener, but 100,000 of them running full-throttle for weeks still adds up to an enormous environmental cost.
The AI Index makes it clear: model size, compute requirements, and emissions are tightly correlated. And while inference costs are falling dramatically, training remains dirty, expensive, and rapidly scaling beyond sustainable levels.
Until the field takes that seriously, we'll keep burning through power, not just data.


