
Welcome back to my ongoing series on the 2025 AI Index Report.
In the last article, we covered the big-picture chaos: models ballooning to absurd sizes, training runs that could power small cities, and the U.S. and China treating AI like an Olympic event. But this time, we're getting technical. Chapter 2 of the report dives into what really matters after the flashy launch announcements and corporate press releases: how well these models actually perform.
Because it turns out, scaling up isn't just a flex. Bigger models and more data genuinely lead to better results… most of the time. But here's the catch: measuring that performance is an art, a science, and more often than you'd like a marketing strategy.
This article breaks down how we evaluate the smartest machines we've ever built, why those evaluations are getting trickier, and how even the benchmarking systems themselves are now playing catch-up. Also, we'll look at how smaller models are getting surprisingly good, why open-source is giving closed models a run for their money, and how some AI systems now solve math problems that would make most of us cry.
Let's get into it.
1. What Are We Even Measuring? A Tour of AI Model Types
Before we go any further into performance metrics and benchmarks, we need to answer a pretty basic question: what kinds of AI models are we actually evaluating?
The AI Index Report breaks this down neatly across several capabilities: language, vision, speech, coding, math, reasoning, agents, robotics. Each with their own quirks, benchmarks, and expectations.
It's worth noting that this discussion focuses specifically on frontier AI models, those pushing the boundaries of generalization, scale, and adaptability. Traditional AI models, such as those used in rule-based systems or classic machine learning pipelines for structured prediction tasks, are not the focus here. These were covered in detail in earlier editions of the AI Index, and their evaluation metrics are comparatively well-established and less contested.
These categories are not always distinct; in practice, many AI models span multiple capabilities, blending techniques and tasks across domains.
Language Models
Language models are AI systems trained to understand, generate, and reason with human language.
Key Tasks:
Text generation and summarizationInstruction following and question answeringCode generation and debuggingChain-of-thought reasoning and logicFunction calling and tool executionRetrieval-augmented generation (RAG)
Language models excel through their versatility, handling everything from tool coordination to math problems while serving as interfaces between humans and digital systems. Recent advances like o1's reasoning capabilities and strong open-weight models like DeepSeek-R1 show rapid progress in the field.
However, these models face challenges including benchmark memorization from messy training data, inconsistent performance based on prompt phrasing, and limited transparency in closed systems. Despite these issues, LLMs continue to lead in both capabilities and real-world applications.
Best Performers: GPT-4o, GPT-4.5, Claude 3.5 Sonnet, o1, o3, Gemini 2.5 Pro, Llama 3.1 405B, DeepSeek-R1, and Mistral Large 24.11.
Vision & Generative Models
These models are trained to process, interpret, or generate visual content. Unlike language models, which deal in abstractions, vision models engage directly with pixels. This category includes both discriminative models (that understand visuals) and generative ones (that create them).
Key Tasks:
Image classification and object detectionScene segmentation and recognitionText-to-image generationText-to-video generationStyle transfer and inpaintingImage captioning and grounding
This category has a unique duality: some models understand images (like OpenCLIP or EVA) while others generate them from scratch (like SDXL-Lightning or Runway Gen-3). The generative side has exploded with diffusion models and transformer-based pipelines pushing visual quality into remarkably realistic territory, with tools like Sora and Lumiere creating videos that can rival real footage for short clips.
However, evaluation remains problematic since assessing image or video quality is subjective and style-dependent. Comparing AI-generated videos is challenging because one might excel at realistic lighting while another offers more creative framing, and the "better" choice depends entirely on whether you want National Geographic realism or A24 artistic style. Current benchmarks struggle to capture this kind of nuance.
Best Performers: ChatGPT 4o, Sora, Lumiere, SDXL-Lightning, Runway Gen-3, Imagen 3, OpenCLIP, EVA-CLIP.
Audio & Speech Models
Audio and speech models are designed to process, interpret, and generate sound: from voice transcription and speech synthesis to music generation and even silent lip reading.
Key Tasks:
Speech-to-text transcriptionText-to-speech synthesisAudio captioning and classificationMusic generation and remixingLip reading and facial speech interpretation
Audio and speech models are uniquely sensitive to timing, tone, and context, focusing not just on recognizing words but understanding how, when, and by whom they're spoken. Models like Whisper and Whisper-Flamingo lead in multilingual transcription, while Stable Audio 2 demonstrates advances in generative music models.
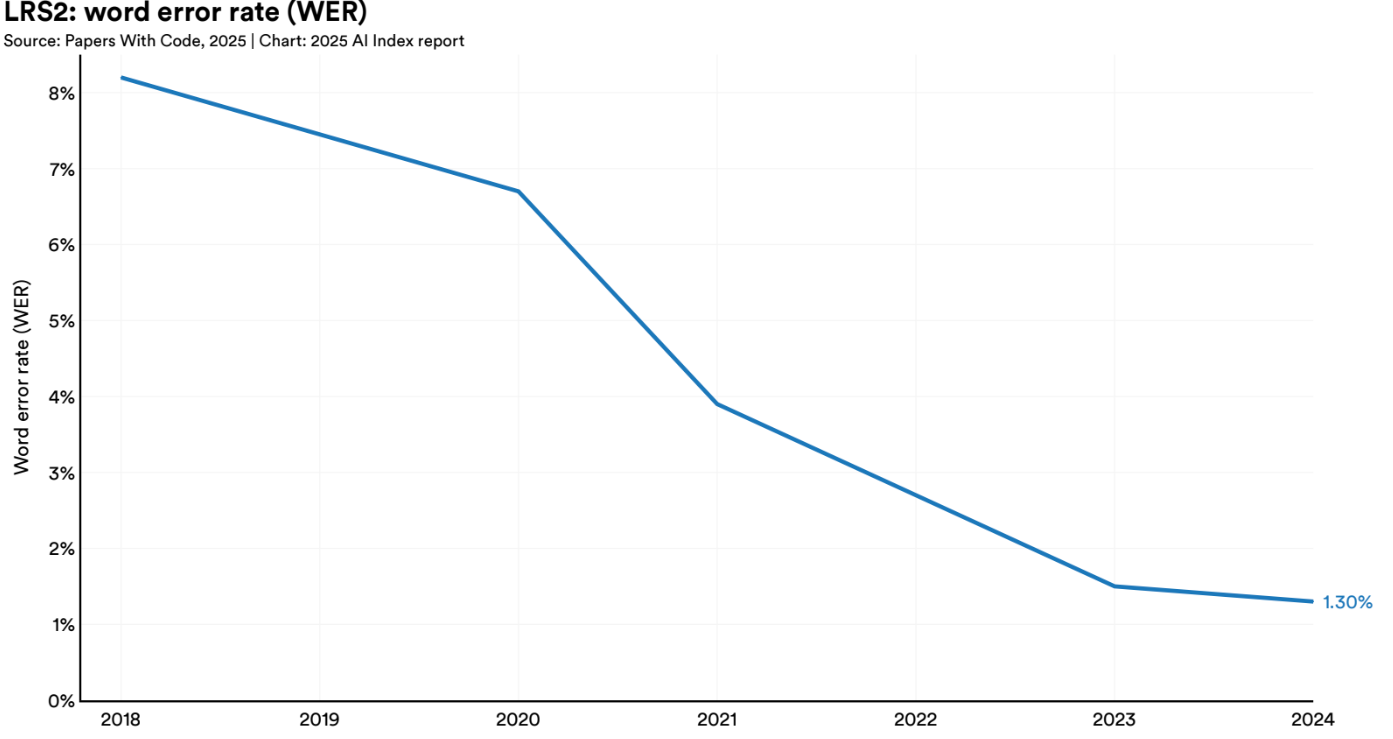
One standout development is lip reading, where Whisper-Flamingo achieved a remarkable 1.3% Word Error Rate on the LRS2 benchmark in 2024, surpassing the previous 1.5% record. This precision suggests these models are approaching benchmark saturation and already outperform many humans at silent speech recognition. The implications are significant for both accessibility tools and privacy concerns, making this a critical space to monitor.
Best Performers: Whisper, Whisper-Flamingo and Stable Audio 2.
Robotics & Embodied AI
Robotics and embodied AI models are designed to operate in the physical world: manipulating objects, navigating environments, or driving vehicles without human input. These systems rely on a combination of perception, planning, and control, often working with real-time data and unforgiving consequences.
Key Tasks:
Object manipulation and graspingNavigation and locomotionHuman-robot interactionVision-based controlAutonomous driving
Robotics and embodied AI models face unique challenges beyond getting the right answer: they must avoid physical harm and operate under latency, physical constraints, and real-world stakes. While transformers are being explored in this space, their complexity makes them problematic for split-second decisions, especially in autonomous driving where delays can have serious consequences.
Self-driving benchmarks demonstrate both promise and caution. Waymo's performance across 25.3 million miles showed 88% fewer property damage claims and 92% fewer bodily injury claims than human drivers, with only 2 injury claims versus the expected 26. Despite these impressive safety statistics, Waymo's operations remain tightly geo-fenced, reflecting the broader tension between growing capabilities and the need for cautious deployment in robotics.
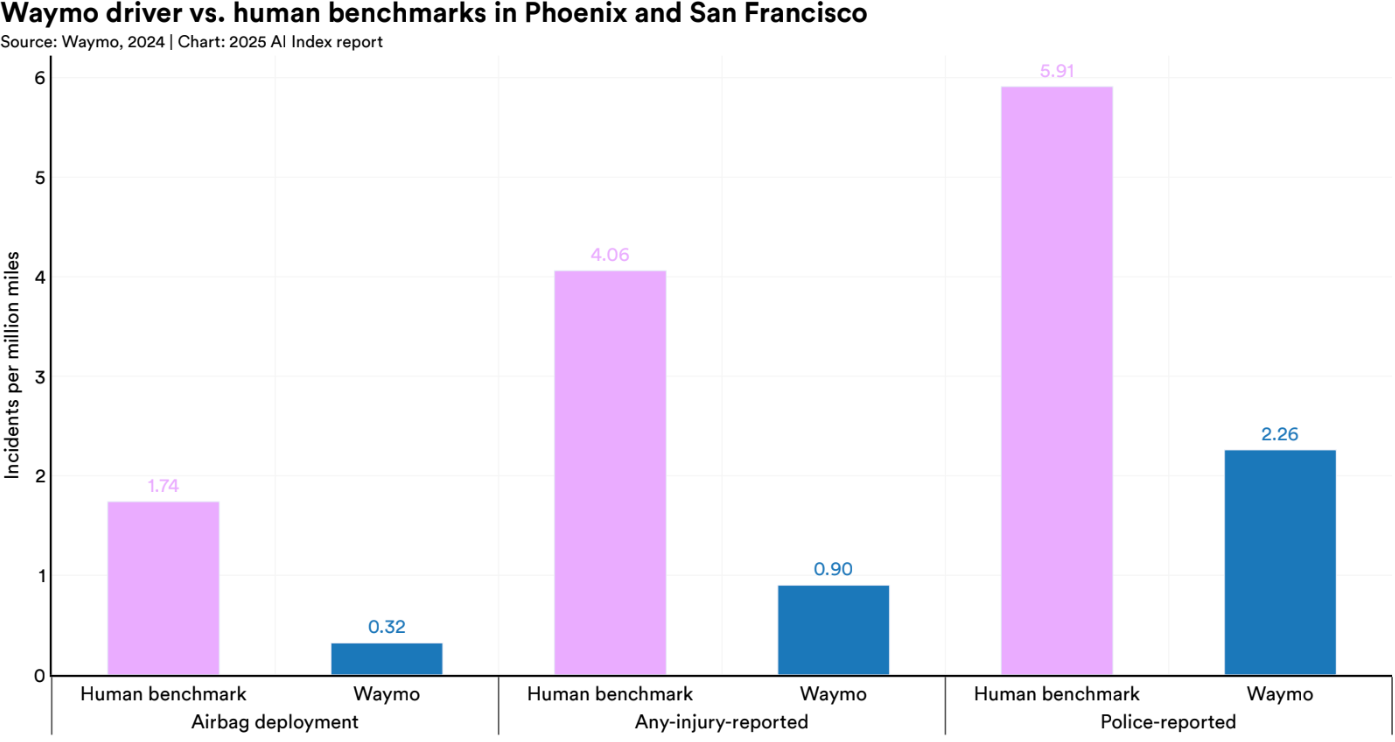
Best Performers: GR00T, RT-X, RT-2, Waymo Driver, SAM2Act
Agentic Systems
Agentic systems are created when you give a language model a memory, some tools, and the ability to make decisions over time. These systems go beyond single-turn Q&A to perform extended tasks: planning, executing, retrying, and sometimes even realizing they made a mistake.
Key Tasks:
Multi-step task executionTool use and coordinationAutonomous planning and retryingInteraction with digital environmentsDecision-making under constraints
Agentic systems are unique in their ability to operate over time, maintaining state, making sequential decisions, and working toward goals with apparent intent. However, they're less about breakthrough models and more about how different components like memory, APIs, user interfaces, and external tools are integrated and orchestrated together.
Many impressive agentic tools like Perplexity, Manus AI and Cursor , aren't powered by exotic new models but rather built on solid LLMs like GPT-4o or Claude, made effective through clever design, context routing, and smart tool integration. But specialized models can play a big role too. A standout example is the xLAM-2 family, specialized Language Agent Models that currently top the Berkeley Function Calling Leaderboard by outperforming previous leaders like watt-tool, showing how precision in tool invocation can rival general-purpose intelligence.
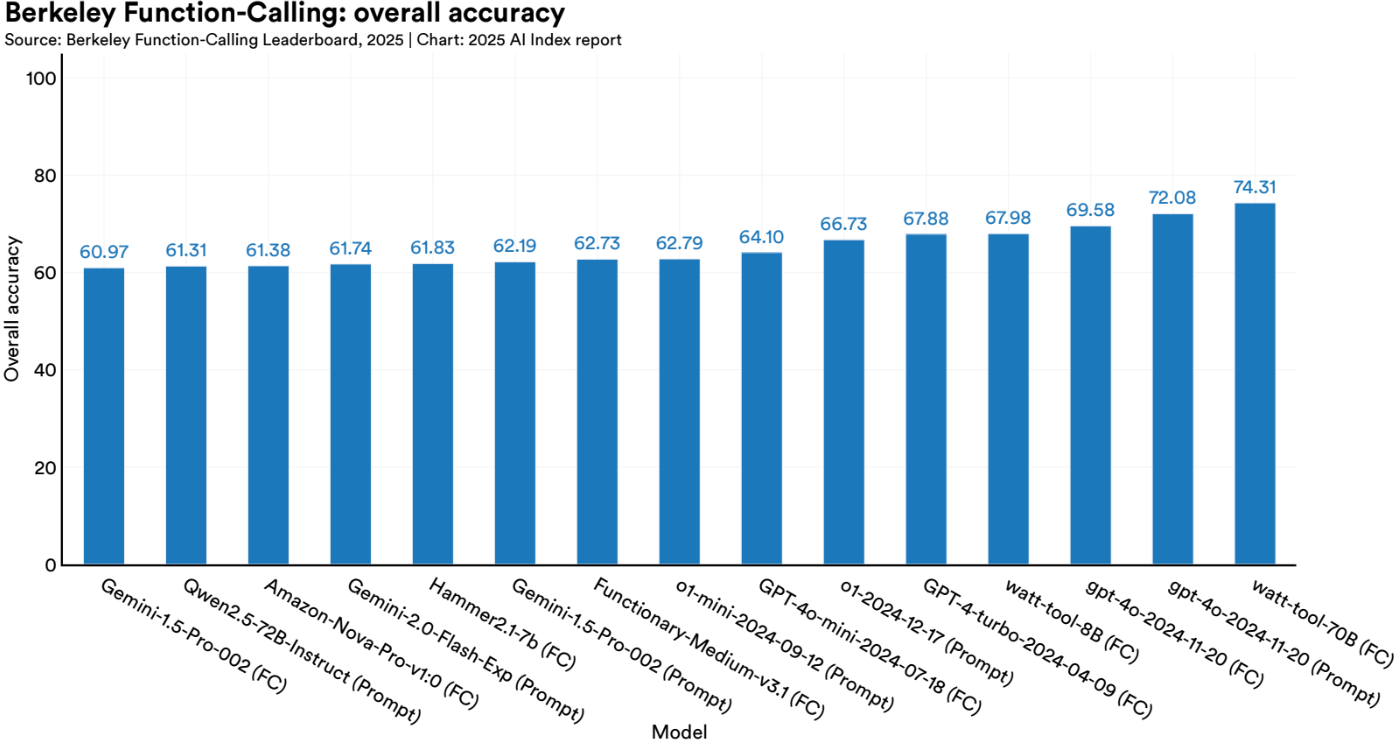
Benchmarks like RE-Bench are emerging to test these systems on long-horizon, multi-step tasks, showing that while agentic AI is competent under tight constraints, it still faces challenges as complexity and time budgets grow. In many ways, they remain like interns: great at first drafts, but not yet ready to run the company.
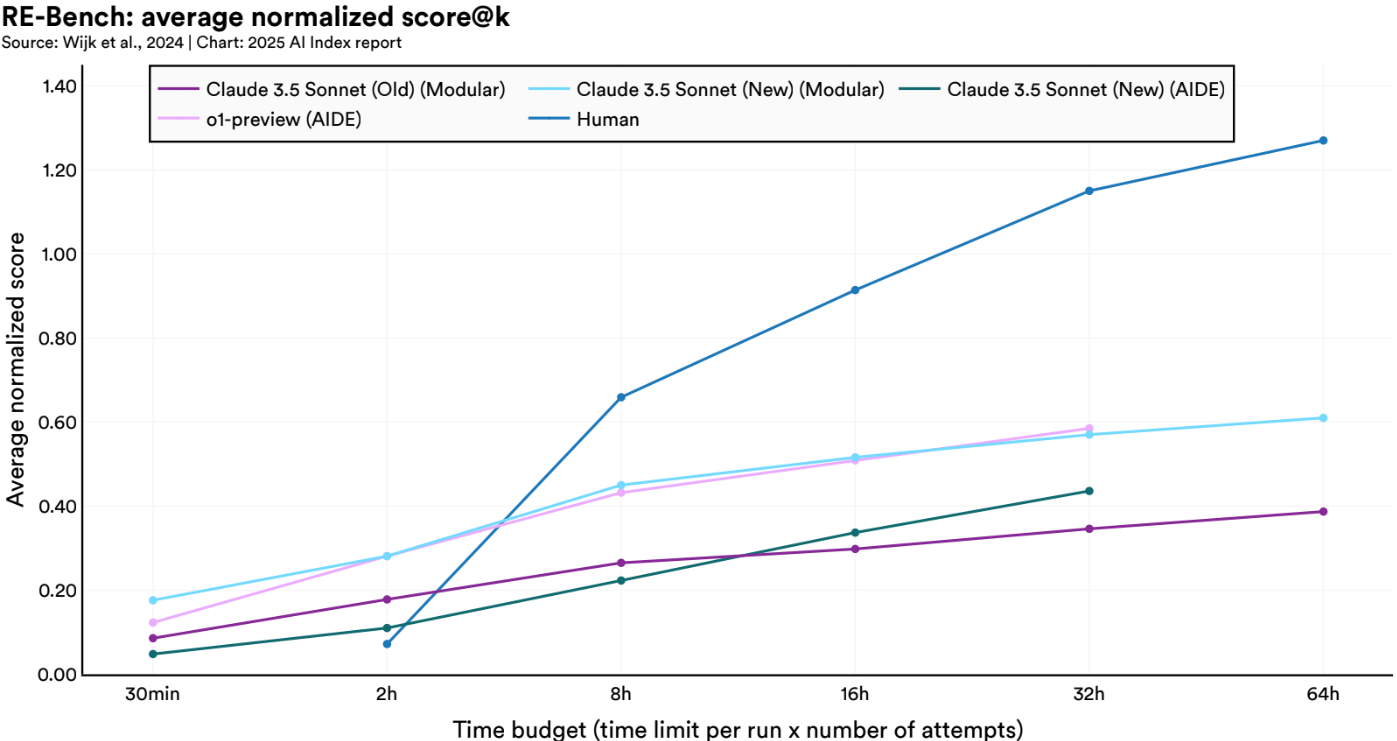
Best Performers: GPT-4o, Claude 3.5 Sonnet and the xLAM-2 model family
2. Current Performance: Who's Actually Winning?
While the leaderboard still features the usual suspects, the balance of power is starting to shift. Open-weight models are rapidly closing the gap with proprietary giants, and the performance differences are now often a matter of nuance, not dominance.
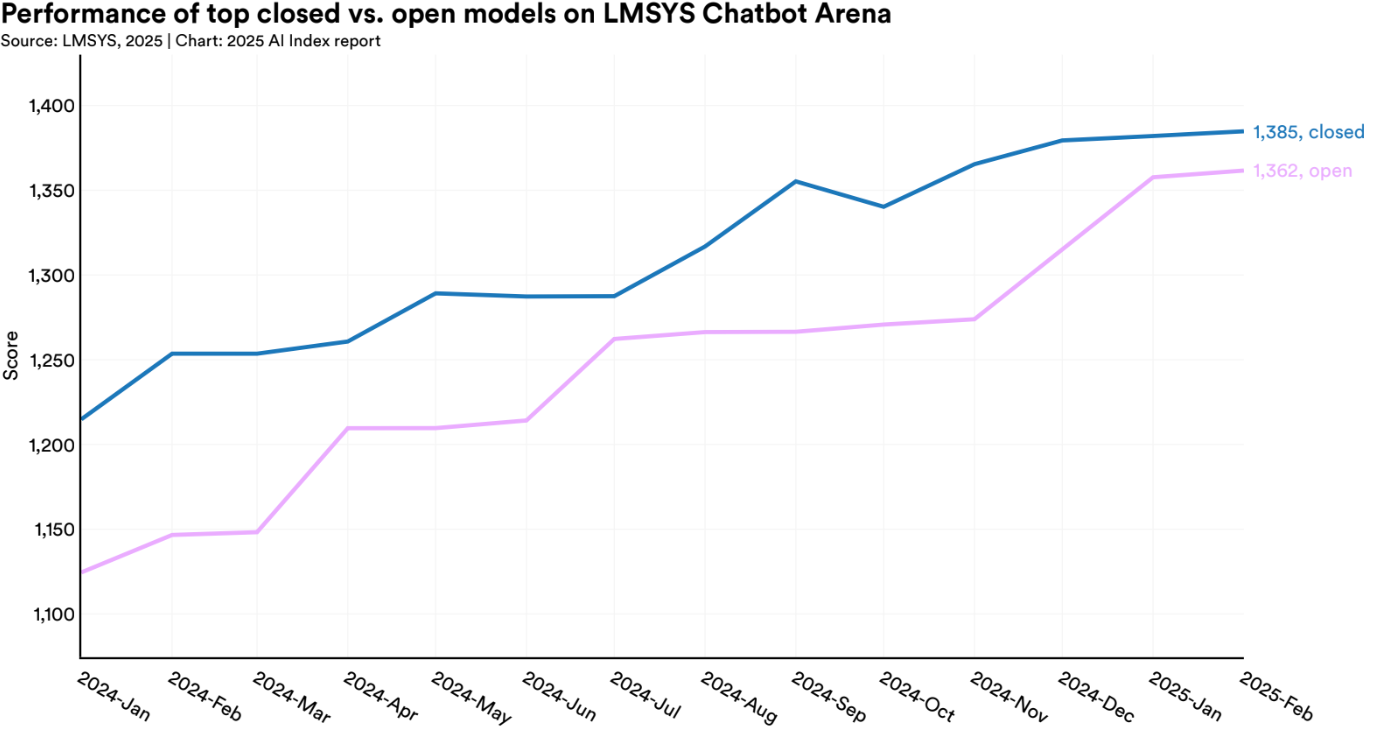
On many benchmarks, open-weight challengers like Mistral Large 24.11, Llama 3.1 405B, and DeepSeek-R1 now rival or outperform models from Anthropic and Google. Open-weight models not only improve transparency and auditability, they're also easier to deploy privately, integrate into internal tools, and optimize for specific needs. According to the Index, the progress made by open models on certain evaluations where the gap was bigger is even more impressive.
The performance gap between China and the U.S. is also narrowing. While U.S. companies still lead in total number of frontier models released, Chinese labs, especially those behind the DeepSeek and Qwen series, are showing up strong in technical benchmarks.
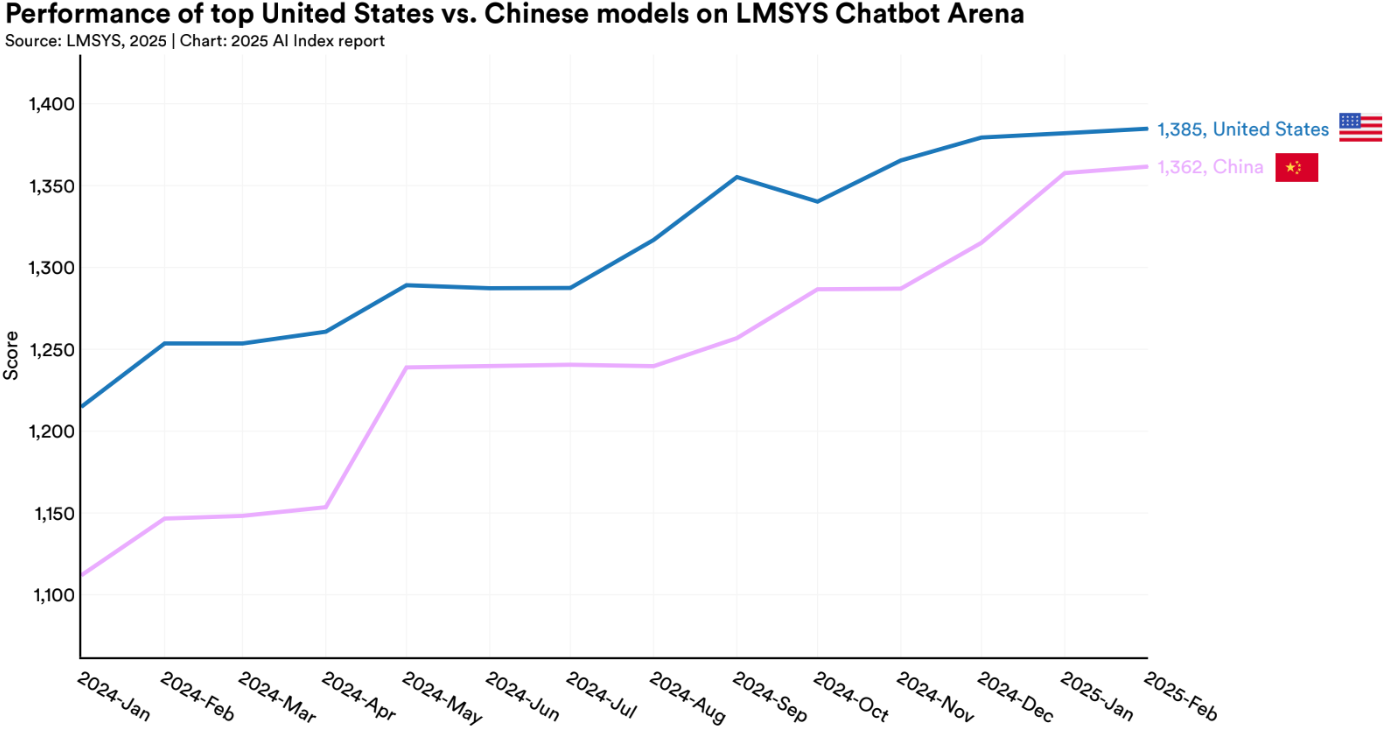
It's also worth noting that many of the newest models, like o3 or Llama 4, aren't yet reflected in this leaderboard, which means these rankings are already slightly outdated.
Reasoning tasks are where this shift is most obvious. o1, using a test-time compute trick (letting the model "think" longer before answering), scored 74.4% on an International Mathematical Olympiad qualifier: a test designed to challenge the best math students in the world. Its successor, o3, went even further, crushing multiple benchmarks in math, science, and logic.
One of the most impressive results came on FrontierMath, a benchmark specifically designed to be well above the difficulty of standard academic tests, with questions that require multi-step deduction, symbolic reasoning, and abstract generalization. o3 destroyed all prior models, showing that with the right combination of training and inference strategy, language models can now tackle problems once considered far beyond their reach.
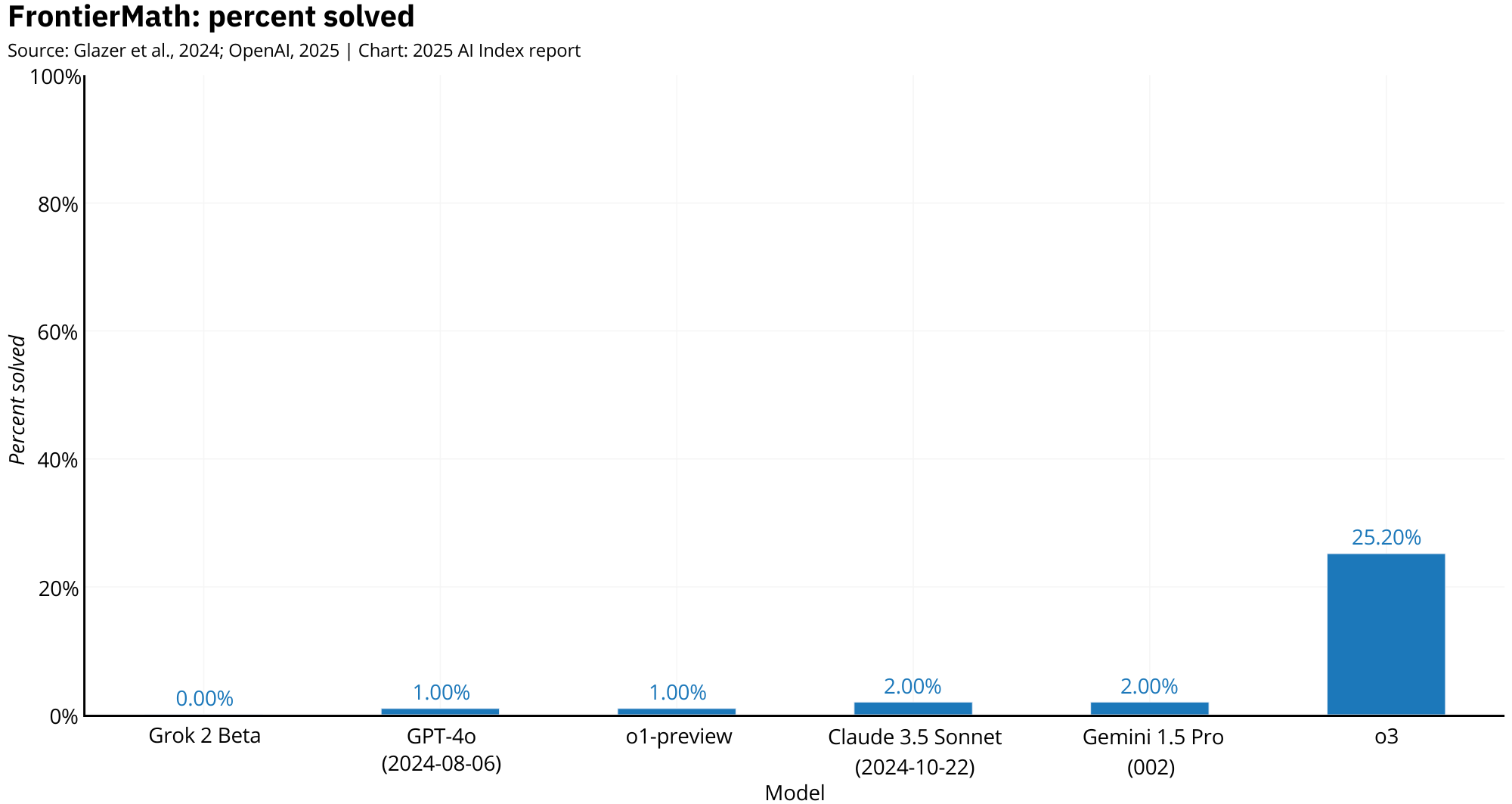
These results highlight how a combination of smarter reasoning and more inference flexibility can outperform even larger, older systems.
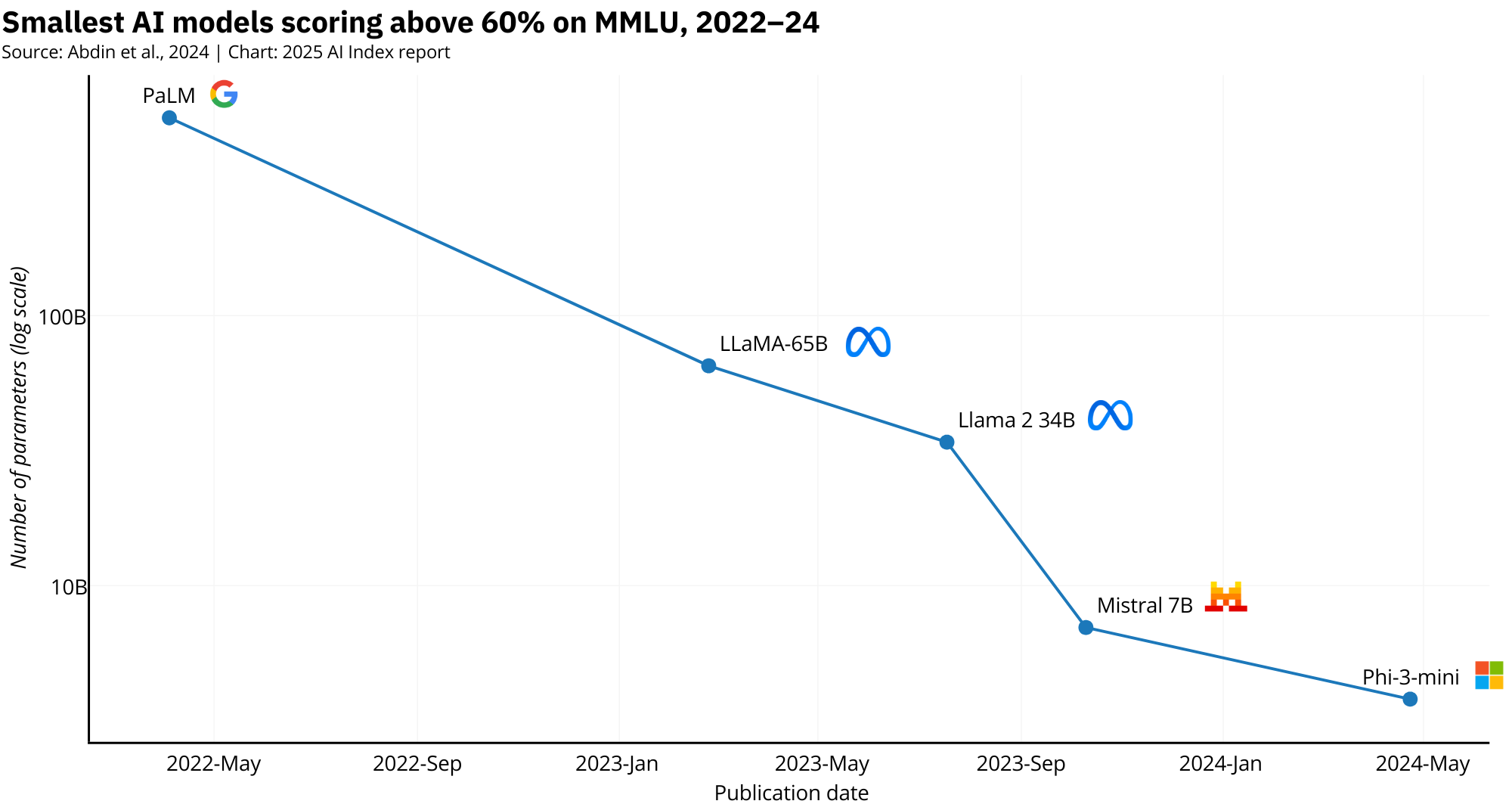
And it's not just about size anymore. Models like Phi-3 Mini, with just 3.8 billion parameters, are starting to edge out giants like the original PaLM, which had a staggering 540 billion parameters (142x difference). That kind of efficiency is great for cost, energy use, and ease of integration.
What's enabling this leap? In many cases, larger models are used to train smaller ones through techniques like distillation, synthetic data generation, or architectural transfer. In other words, big models are teaching small ones how to be smart. The result: compact systems that are easier to deploy, fine-tune, and secure, without giving up too much capability.
3. Innovations That Allowed Models to Perform Better
We've finally hit the point where performance isn't just about stacking more parameters and burning through more GPUs. Which is good news, not everyone has the budget (or the electricity bill tolerance) of a hyperscaler. Model quality is also shaped by architectural choices, smarter inference strategies, and how well models are integrated into real-world systems. Here's what's actually powering the jump in performance:
Reasoning Improvements & Test-Time Compute
Reasoning is how models think through problems step by step. Models like o1, o3, and Claude 3.5 use chain-of-thought reasoning and multiple passes to reach more accurate conclusions, while test-time compute allows them to explore several answers and reasoning paths before selecting the best outcome, making them more deliberate rather than just faster.
Mixture-of-Experts (MoE)
MoE architectures like Mixtral 8x7B reduce the brute-force nature of traditional LLMs by activating only a fraction of their total parameters for each task. Instead of firing up all neurons for every input, the model selects specialized subnetworks or "experts" depending on what the prompt requires, saving compute, speeding up inference, and making models far more scalable in deployment environments.
Retrieval-Augmented Generation (RAG)
LLMs don't just memorize information but also pull it in dynamically. RAG lets models retrieve relevant documents, facts, or structured data before generating a response, grounding their outputs in external reality. It's how models can stay accurate without retraining every time the world changes.
Multimodal Integration
Multimodal models like GPT-4o, Claude 3.5 Sonnet, and Gemini 2.5 Pro can process text, images, and audio together, responding as if those inputs were just one big conversation. This fusion allows them to analyze screenshots, transcribe speech, or explain charts alongside natural language.
Longer Context Windows
Long context models like Gemini 2.5 Pro and GPT-4o don't forget things halfway through a task. With token windows in the hundreds of thousands, these models can now process entire books, legal contracts, or software repositories without breaking the thread. No more workarounds, chunking hacks, or half-remembered context.
Small Models Getting Smarter
Compact models like Phi-3 Mini, Gemma 2B, and Qwen 1.5 1.8B are trained using techniques like distillation and synthetic data, letting them absorb the skills of much larger models without the compute burden. Many punch far above their weight, performing on par with models 10–100x their size. They're smaller, faster, cheaper, and surprisingly capable.
Infrastructure & Efficiency
Nvidia H100s and similar accelerators deliver more FLOPs per watt, enabling faster training and cheaper inference. Labs like Mistral and Mosaic are also optimizing for energy efficiency and in some cases using greener power sources to train models from the ground up. It's less glamorous than a benchmark win, but critical for real-world viability.
4. The Importance of Benchmarking and the Mess It's In
Benchmarks have played a crucial role in making sense of AI's explosive progress, giving us a structured way to compare models, track capabilities, and quantify improvement.
But as models have become more powerful and general-purpose, many benchmarks have started to fall behind. Some are now so easily gamed, contaminated, or narrow that they say more about prompt formatting than true model capacity. Researchers are actively working to close the gap by proposing harder tasks, refining evaluation protocols, and building new tools to keep pace with today's frontier models.
"The rapid evolution of LLMs is compelling researchers to rethink and refine evaluation methodologies." - AI Index 2025
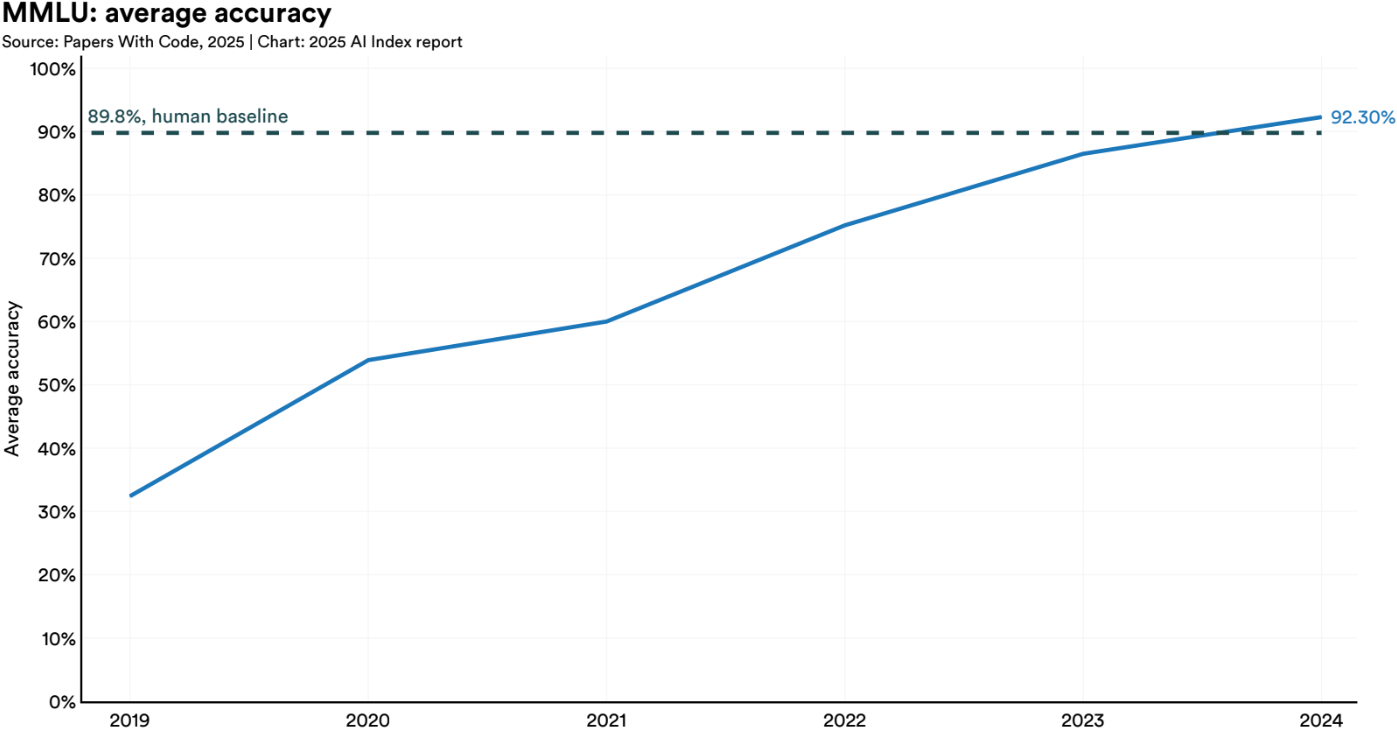
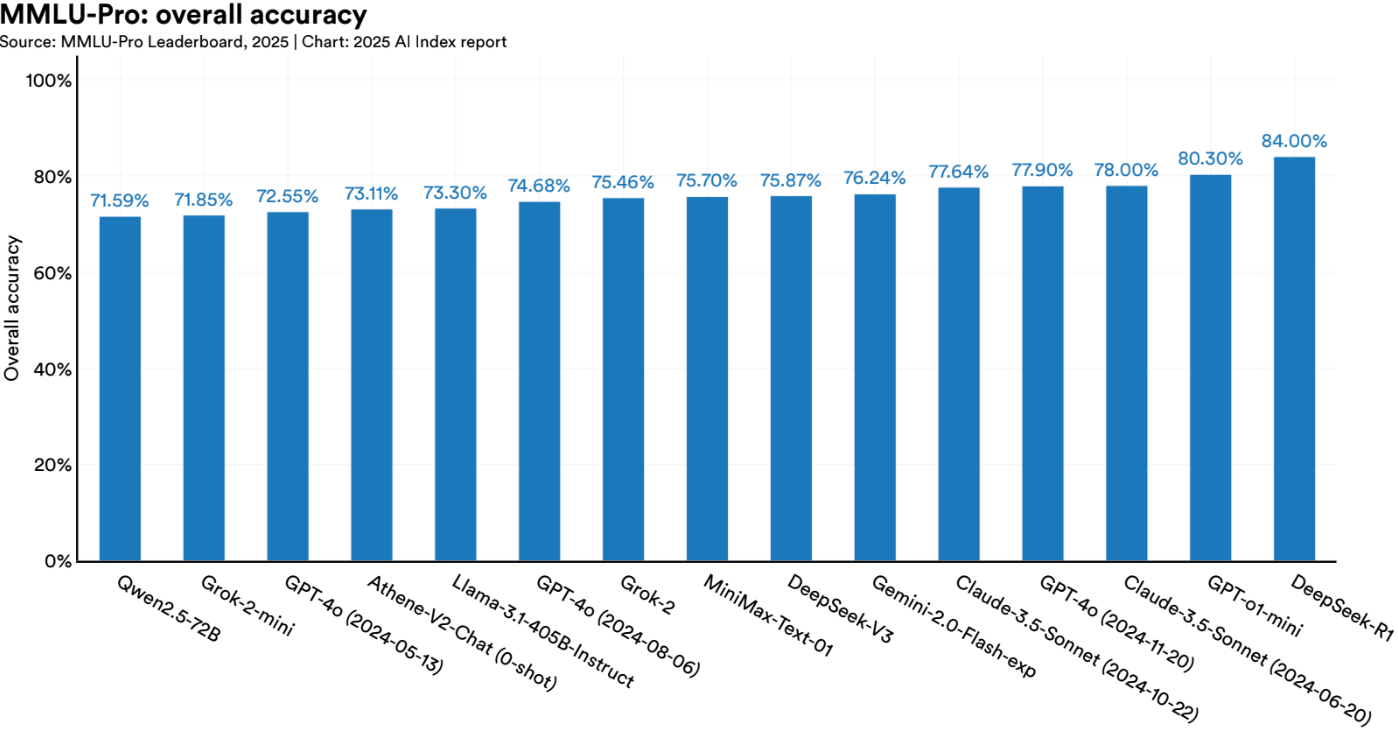
Still, the cracks are hard to ignore. Many widely used evaluations have been pushed to their limits, with new models instantly maxing them out. Tasks like MMLU, GSM8K, HumanEval, and MATH have become so saturated that top models routinely score in the 90s. Claude 3.5 Sonnet scores 97.7% on GSM8K, o3 hits 97.9% on MATH, and GPT-4o is maxing out standard academic benchmarks.
And even when a benchmark seems difficult, there's no guarantee it's clean. Contamination is a growing concern: many benchmarks are publicly available and end up in training datasets, so the model isn't solving a hard problem but recalling something it's already seen.
And when benchmarks are clean, they're often fragile. Small changes in prompt phrasing, formatting, or context can cause massive performance swings. Since companies rarely disclose their exact prompting setups, it's hard to know whether scores reflect genuine skill or not. Researchers are pushing for standardized prompting protocols and transparent reporting, but until that becomes the norm, results remain worryingly easy to manipulate.
Then there's the human baseline, a concept that sounds solid but quickly falls apart under scrutiny. Benchmarks often declare that a model has reached or surpassed "human-level performance," but they rarely define what that actually means. Are we talking about trained experts? Undergraduate students? The average person? Without a consistent, transparent definition, these comparisons become meaningless.
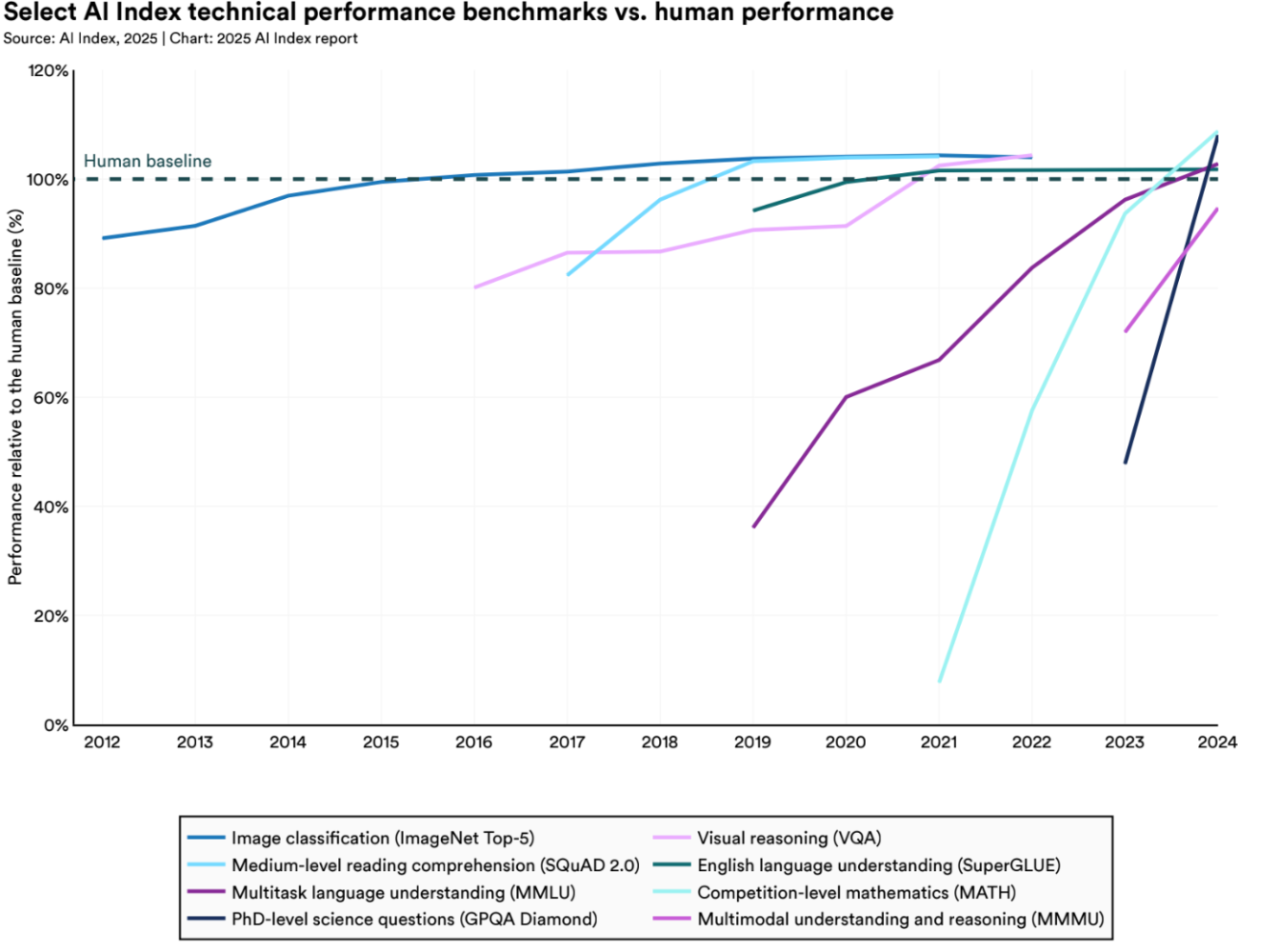
The AI Index includes this type of comparison, but even there, it's clear how slippery the baseline is. At best, it's a rough reference point. At worst, it's a marketing line pretending to be science.
To make matters worse, there's a growing gap between what model developers report and what third-party evaluations find. A model might post state-of-the-art numbers in a launch paper, only to underperform in independent testing. In some cases, scores drop by double digits. If results can't be reproduced, then they're not benchmarks but ads. Take Llama 4: rumors suggest Meta submitted a specially optimized, non-public version for evaluation that outperformed what was eventually released.
This is a governance problem. Benchmarks influence which models get deployed in hospitals, courts, and corporations. If we're optimizing for the wrong metrics or letting flawed benchmarks dictate the narrative, we're making bad decisions at scale.
And if good AI governance is the goal, then general-purpose benchmarks aren't enough. We need specialized evaluations that reflect the tasks AI systems are actually used for. A chatbot, legal assistant, and function-calling agent don't need the same skills, so why use the same metrics? That's what makes tools like the Berkeley Function Calling Leaderboard valuable: they test specific, high-impact abilities. Good AI governance starts with choosing the right model for the job and that means having the right benchmark to evaluate it.
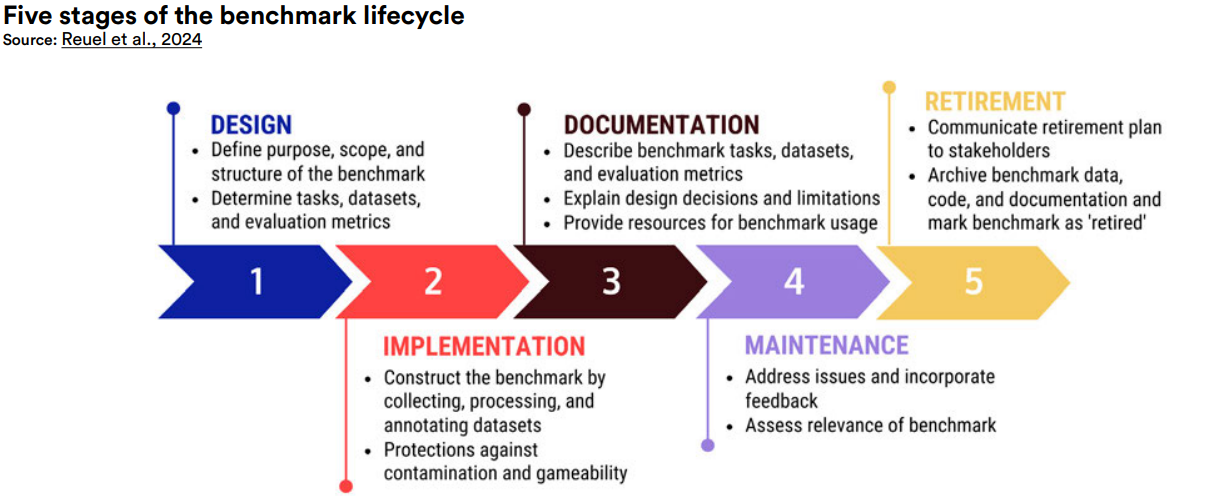
To fix the growing gap between model capabilities and evaluation quality, researchers are developing more robust frameworks. BetterBench, by Reuel et al. (2024) proposed a 46-criteria framework spanning the entire benchmark lifecycle, from design to contamination tracking and maintenance. It's a step toward making benchmarking more scientific and less theatrical. If we want AI development to be responsible, then the way we measure progress has to be too.
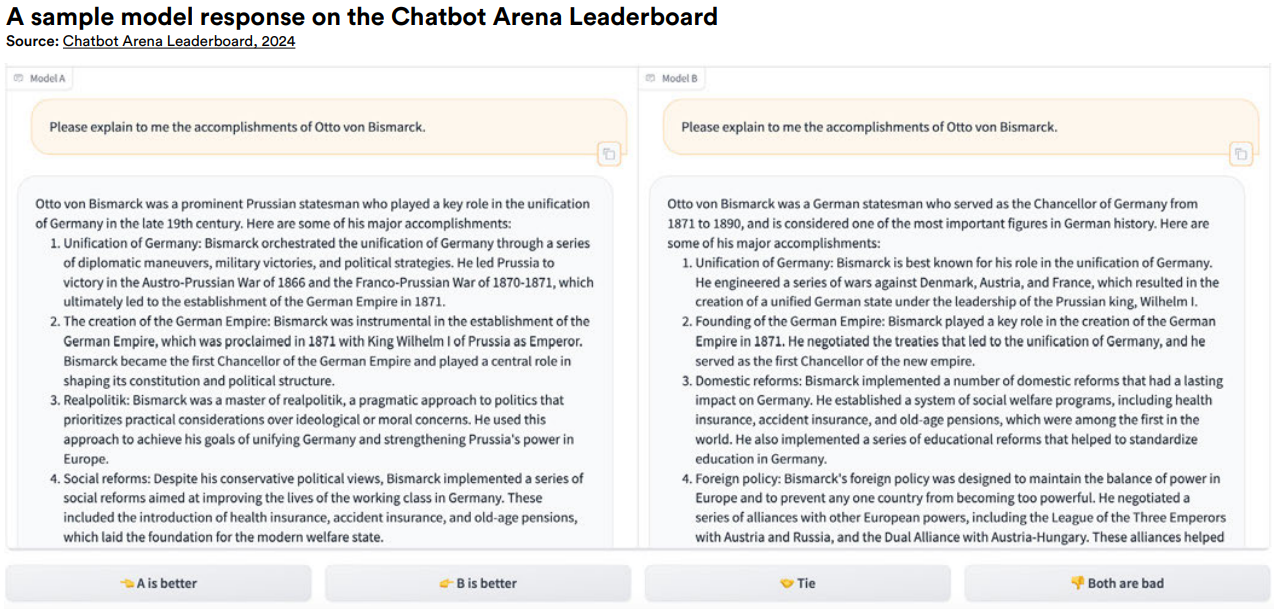
Some groups are rethinking benchmarking entirely. Chatbot Arena crowdsources model comparisons through blind A/B tests where real users vote on responses without knowing which model wrote them. It's messy and subjective, but captures how people actually experience model quality in the wild.
Building on that idea, Arena-Hard-Auto focuses on tough, user-generated queries (from Chatbot Arena), evaluating how models handle complex or adversarial prompts that don't show up in traditional benchmarks. It's a stress test that cuts through the fluff.
And then there's the original benchmark, the Turing Test. For decades, it was the gold standard: could an AI system convince a human that it was human? Well, that milestone was recently beaten. In blind evaluations, language models now pass as human, with response indistinguishability becoming the norm in certain contexts. It's a historic moment and one I wrote about in more detail.
AI is evolving faster than our ability to evaluate it. Models master new tasks faster than we can invent ways to test them. If benchmarks don't catch up or keep rewarding superficial wins, we risk mistaking polish for progress. In a field spanning search engines to courtrooms, that's not just a technical problem but a governance one.
5. 10 Noteworthy Models That Slipped Under the Radar
Beyond the headline giants: GPT-4o, Claude 3.5, Gemini 2.5 Pro, there's an entire layer of innovation that rarely gets the spotlight. Fortunately, the AI Index doesn't just highlight the usual suspects but also many other overlooked models. Here are some of the standout models and tools that didn't dominate the front page but still deserve your attention:
Currently topping the Berkeley Function Calling Leaderboard, xLAM-2 is engineered specifically for structured function calling. These Language Agent Models are optimized for invoking external tools and APIs rather than general chat, built for orchestration and control. It's a reminder that specialized benchmarks matter for use cases where precision and structure beat verbosity.
At only 494 million parameters, it's pushing the boundaries of lightweight LLMs while remaining functional. It scored 45.4% on MMLU, respectable given its size. But raw benchmark performance isn't the whole story for these models, their true value comes from being fine-tuned for specific tasks where efficiency and speed matter more than leaderboard rankings.
One of the most interesting open-weight models of 2024, developed in Abu Dhabi by the Technology Innovation Institute, it's the first open-source State Space Language Model, offering faster, more memory-efficient performance than traditional Transformers. Despite its modest size, it outperforms comparable models like Llama 3.1 8B on reasoning benchmarks, proving innovation isn't limited to the usual power centers.
Jamba, from AI21 Labs, is a hybrid model blending Transformer, Mamba, and MoE architectures for accuracy, efficiency, and throughput. It supports 256,000 token context windows, runs on single GPUs, and includes enterprise features like function calling and JSON output without requiring massive infrastructure.
Stable Audio 2 offers full-length, structured tracks up to five minutes long with intros, development, and outros. Built on latent diffusion, it features audio-to-audio prompting for transforming samples using text instructions. It's powered by a diffusion transformer and uses ethically licensed AudioSparx data. While fidelity sometimes lags behind rivals like Suno, it excels in structure, flexibility, and responsible design.
Whisper-Flamingo brings lip reading into speech recognition by combining audio with visual cues like lip movements and facial expressions, massively improving performance in noisy environments. Built on OpenAI's Whisper and inspired by DeepMind's Flamingo, it uses smart attention to fuse audio and video in a single, unified model that's multilingual across nine languages. Whether it's crowded meetings, public spaces, or accessibility tools, it sets a new standard for understanding speech even when hearing clearly isn't an option.
NotebookLM's "Audio Overview" feature transforms your notes, documents, and web content into a conversational, AI-generated podcast hosted by two lifelike virtual presenters. Unlike typical audio summaries, you can actually interact with the hosts, asking follow-up questions or steering the conversation in real time. The tool pulls from uploaded sources like Google Docs, websites, or YouTube transcripts to create engaging discussions that help you understand complex information more naturally, turning passive material into active dialogue without touching a microphone.
Salesforce's Moirai is a universal time series forecasting model that generalizes across domains, variables, and frequencies with zero-shot performance. It uses a patch-based Transformer and "any-variate" attention to handle long, multivariate sequences without retraining. Available in multiple sizes (14M to 311M parameters), Moirai delivers state-of-the-art results on forecasting benchmarks across everything from sales projections to energy demand, with a Mixture-of-Experts variant pushing performance even further.
SAM2Act is a next-generation robotic manipulation model combining visual foundation models, 3D reasoning, and episodic memory for precise, complex tasks. Enhanced with memory modules in SAM2Act+, it achieved state-of-the-art success rates on benchmarks like RLBench while showing robust real-world performance. SAM2Act isn't just making robots more capable but helping them remember what they did five steps ago and why.
Developed by NVIDIA, GR00T is an ambitious foundation model for general-purpose humanoid robots, combining vision, language, and motor control through a dual architecture for reasoning and action generation. Backed by Jetson Thor hardware and adopted by firms like Boston Dynamics and Figure AI, it's a platform aiming to put intelligent brains into every robot. These specialized models reflect a use-case-driven frontier where intelligence isn't just broad but applied.


